Описание сервисов#
В этом разделе представлена более подробная информация о функциях сервисов LP.
Базы данных могут быть не указаны на поясняющих рисунках.
См. таблицу с потреблением ресурсов каждым из перечисленных ниже сервисов в разделе "Потребление ресурсов сервисами".
Общая информация о сервисах#
«Рабочие процессы»#
Для сервисов LUNA PLATFORM можно задавать количество "рабочих процессов" для использования дополнительных ресурсов и памяти системы для обработки запросов к сервису. Сервис автоматически запускает несколько процессов и распределяет запросы между процессами.
При запуске сервиса в Docker-контейнере, количество "рабочих процессов" задается с помощью параметра WORKER_COUNT.
Например, если выставить значение WORKER_COUNT=2 для сервиса Faces, то сервис будет потреблять в 2 раза больше ресурсов и памяти.
Обратите внимание на количество доступных основных компонентов на вашем сервере при использовании этой функции.
Использование "рабочих процессов" – это альтернативный способ линейного масштабирования сервисов. При увеличении количества экземпляров сервисов на одном сервере рекомендуется использовать дополнительные "рабочие процессы".
Не рекомендуется использовать дополнительные "рабочие процессы" для сервиса Remote SDK, если он использует графический процессор. Проблемы могут возникнуть, если возникнет нехватка памяти графического процессора, и "рабочие процессы" будут мешать друг другу.
Автоматическая перезагрузка конфигураций#
Сервисы LP поддерживают автоматическую перезагрузку конфигураций. При изменении параметра, он автоматически обновляется для всех экземпляров соответствующих сервисов. Если эта функция включена, нет необходимости перезапускать сервисы вручную.
Эта функция доступна для всех настроек, предусмотренных для каждого сервиса Python. Необходимо включать эту функцию вручную при каждом запуске сервиса. См. раздел "Включение автоматической перезагрузки конфигурации".
Начиная с версии 5.5.0, перезагрузка конфигурации для сервисов Faces и Python Matcher выполняется в основном путем перезапуска соответствующих процессов.
Ограничения#
Сервис может работать некорректно при применении новых настроек. Настоятельно рекомендуется не отправлять запросы в сервис при изменении важных настроек (настройки БД, список рабочих плагинов и др.).
Применение новых настроек может привести к перезапуску сервиса и сбросу кэшей (например, кеш сервиса Python Matcher). Например, при изменении версии биометрического шаблона по умолчанию будет перезапущена платформа LP. Изменение уровня ведения журнала не вызывает перезапуска сервиса (если было указано допустимое значение параметра).
Включение автоматической перезагрузки конфигурации#
Можно включить эту функцию, указав функцию --config-reload в командной строке. В Docker конейнерах эта функция включается с помощью параметра "RELOAD_CONFIG".
Можно указать период проверки конфигурации в аргументе командной строки --pulling-time. По умолчанию установлено значение 10 секунд. В Docker конейнерах эта функция включается с помощью параметра "RELOAD_CONFIG_INTERVAL".
Процесс обновления конфигураций#
Сервисы LP периодически получают настройки из сервиса Configurator или файлов конфигурации. Это зависит от способа получения конфигураций для конкретного сервиса.
Каждый сервис сравнивает свои имеющиеся настройки с полученными:
-
При изменении настроек сервиса они будут запрошены и применены.
-
Если запрос конфигураций не удался, сервис продолжит работу без внесения каких-либо изменений в существующие конфигурации;
-
Если проверка соединений с новыми настройками не удалась, сервис повторит попытку запроса новых конфигураций через 5 секунд. Сервис отключится после 5 неудачных попыток;
-
-
Если текущие настройки и новые запрошенные настройки совпадают, сервис Configurator не будет выполнять никаких действий.
Выполнение переноса базы данных#
Необходимо выполнить скрипт переноса, чтобы обновить структуру базы данных при обновлении до новых сборок LP. По умолчанию перенос автоматически применяется при запуске скрипта db_create.
Этот метод может быть полезен при необходимости выполнить откат к предыдущей сборке LUNA PLATFORM или обновить структуру базы данных без изменения сохраненных данных. В любом случае, перед применением любых изменений рекомендуется создать резервную копию вашей базы данных.
Можно запускать перенос из контейнера или использовать одиночную команду.
Одиночная команда#
Ниже приведен пример для сервиса Tasks.
docker run \
-v /etc/localtime:/etc/localtime:ro \
-v /tmp/logs/tasks:/srv/logs \
--rm \
--network=host \
dockerhub.visionlabs.ru/luna/luna-tasks:v.3.24.0 \
alembic -x luna-config=http://127.0.0.1:5070/1 upgrade head
Запуск из контейнера#
Чтобы выполнить перенос из контейнера, необходимо выполнить следующие действия (пример приведен для сервиса Configurator):
-
Зайти в Docker-контейнер сервиса. См. "Вход в контейнер" в руководстве по установке LP 5.
-
Запустить перенос.
Для большинства сервисов параметры конфигурации должны быть получены от сервиса Configurator, а команда имеет следующий вид:
alembic -x luna-config=http://127.0.0.1:5070/1 upgrade head
-x luna-config = http://127.0.0.1:5070/1 – указывает, что параметры конфигурации для переноса должны быть получены от сервиса Configurator.
Для сервиса Configurator параметры берутся из файла "srv/luna_configurator/configs/config.conf".
Для сервиса Configurator следует использовать следующую команду:
alembic upgrade head
- Выход из контейнера. Контейнер будет удален после выхода.
exit
Сервис API#
LUNA API – это веб-сервис распознавания лиц. Он предоставляет интерфейс RESTful для взаимодействия с другими сервисами LUNA PLATFORM.
С помощью сервиса API можно отправлять запросы другим сервисам LP и выполнять следующие задачи:
-
обработка и анализ изображений:
-
распознавание лиц/тел на фотографиях;
-
оценка атрибутов лица (возраст, пол, этническая принадлежность) и параметров лица (поза головы, эмоции, направление взгляда, атрибуты глаз, атрибуты рта);
-
оценка параметров тела (возраст, пол, аксессуары, головной убор, цвета верхней и нижней одежды, тип рукавов);
-
-
поиск похожих лиц/тел в базе данных;
-
хранение полученных атрибутов лиц в базах данных;
-
создание списков для поиска;
-
сбор статистики;
-
гибкое управление запросами для удовлетворения требований обработки пользовательских данных.
Сервис Remote SDK#
Сервис Remote SDK используется для:
- обнаружения лиц и оценки параметров лиц,
- обнаружения тел и оценки параметров тел,
- проверки изображений по указанным порогам и оценки параметров изображений,
- создания нормализованных изображений,
- извлечения базовых атрибутов и биометрического шаблона, в т.ч. агрегированных,
- обработки изображений на основе политик обработчиков и верификаторов.
Обнаружение лиц, тел, извлечение БШ, оценка параметров и атрибутов выполняются с помощью нейронных сетей. Алгоритм со временем совершенствуется и появляются новые нейронные сети. Они могут отличаться друг от друга по производительности и точности. Выбирать нейронную сеть следует исходя из бизнес требований к работе системы.
Сервис Remote SDK с графическим процессором#
Сервис Remote SDK может использовать GPU для вычислений вместо CPU. Для каждого экземпляра сервиса Remote SDK используется один GPU.
Извлечение атрибутов на графическом процессоре предусмотрено для получения максимальной производительности. Для входящих изображений выполняется пакетная обработка. При этом снижаются затраты на вычисления для изображения, но не обеспечивается минимальная задержка для каждого изображения.
Ускорение графического процессора разработано для приложений с высокой нагрузкой, где выполняются тысячи запросов в секунду. Нецелесообразно использовать ускорение графического процессора в сценариях с небольшой нагрузкой, если задержка имеет значение.
Агрегирование#
На основе всех переданных в одном запросе изображений может быть получен единый набор базовых атрибутов и агрегированный биометрический шаблон. Кроме того, во время создания события выполняется агрегация полученных значений Liveness, эмоций, наличия медицинской маски для лиц и верхней и нижней частей тела, пола, возраста и аксессуаров для тел.
Для агрегированного БШ результаты сравнения являются более точными. Агрегирование рекомендуется использовать при получении с одной камеры нескольких изображений. Не гарантируется, что агрегированные БШ обеспечат улучшения в других случаях.
Считается, что каждый параметр агрегирован из БО. Для активации агрегирования атрибутов необходимо использовать параметр "aggregate_attributes" в запросах "extract attributes" (только для лиц) и "sdk". Агрегация значений Liveness, эмоций и масок для лиц и верхней части тела, пола, возраста и аксессуаров для тел доступна с помощью параметра "aggregate_attributes" в запросе "generate events", при условии, что ранее в обработчике была произведена оценка этих параметров, а также в запросе "sdk".
В ответе выдается массив "sample_id", даже если в запросе использовался только один биометрический образец. В этом случае в массив включается один идентификатор БО.
Форматы биометрических шаблонов#
В LUNA PLATFORM доступна работа со следующими форматами биометрических шаблонов:
|
Формат БШ |
Содержание файлов |
Размер |
|---|---|---|
|
SDK |
Набор байтов (сам БШ). |
Размер зависит от версии нейронной сети (см. раздел "Нейросети") |
|
Набор байтов, указывающих версию. |
Размер равен 4 байтам. |
|
|
Набор байтов сигнатуры. |
Размер равен 4 байтам. |
|
|
Raw |
Набор байтов (сам БШ), закодированный в Base64 |
Размер зависит от версии нейронной сети (см. раздел "Нейросети") |
|
XPK-файлы |
Файлы, которые хранят БШ в формате SDK |
Размер зависит от количества БШ внутри файла |
Примечание. Форматы Raw и XPK-файлы являются устаревшими. Рекомендуется работать с форматом SDK.
SDK и Raw форматы могут быть напрямую привязаны к лицу или сохранены во временный атрибут (см. "Создание объектов с использованием внешних данных").
В большинстве запросов на извлечение, биометрический шаблон записывается в базу данных как набор байтов, не выдаваясь в теле ответа.
Существует несколько запросов, с помощью которых можно получить биометрический шаблон в формате SDK:
- запрос "sdk";
- запрос "get temporary attributes и "get temporary attribute.
С помощью LUNA PLATFORM невозможно получить биометрические шаблоны в формате Raw и SDK. Можно использовать другое программное обеспечение VisionLabs для получения данных форматов (например, LUNA SDK). Биометрические шаблоны, полученные с помощью вышеописанных ресурсов или с помощью программного обеспечения VisionLabs называются "сырыми" биометрическими шаблонами.
Использование "сырых" биометрических шаблонов для сравнения
Вышеописанные форматы биометрических шаблонов могут быть использованы в запросах на использование "сырых" биометрических шаблонов.
Внешний БШ можно использовать как эталон в следующих ресурсах:
- "/matcher/faces",
- "/matcher/bodies",
- "/matcher/raw",
- "/handlers/{handler_id}/events", когда установлена схема тела запроса "multipart/form-data",
- "/verifiers/{verifier_id}/verifications", когда установлена схема тела запроса "multipart/form-data",
- "/verifiers/{verifier_id}/raw".
Внешний БШ можно использовать как кандидат в следующих ресурсах:
Создание объектов с использованием внешних данных#
Можно создать временный атрибут или лицо, отправив внешние базовые атрибуты и БШ в LUNA PLATFORM. Таким образом, вы можете хранить эти данные во внешнем хранилище и отправлять их в LP только для обработки запросов.
Можно создать атрибут или лицо с помощью:
- базовых атрибутов и их БО;
- биометрических шаблонов (БШ в чистом виде в Base64 или БШ SDK в Base64);
- базовых атрибутов и биометрических шаблонов с соответствующими данными.
Биометрические образцы не являются обязательными и могут не использоваться при создании атрибута или лица.
Более подробная информация приведена в справочном руководстве сервиса API, в разделах "create temporary attribute" и "create face".
Проверка изображений на соответствие стандартам#
Сервис Remote SDK позволяет проверить изображения по стандарту ISO/IEC 19794-5:2011 или указанным пользователем порогам с помощью трех способов:
- запрос "iso"
- параметр "estimate_face_quality" запроса "detect faces"
- группа параметров "face_quality" политики "detect_policy" запроса "generate events"
Например, необходимо, выполнить проверку является ли изображение подходящего формата, указав в качестве удовлетворительного условия форматы "JPEG" и "JPEG2000". Если изображение подходит под данное условие, система вернет значение "1", если же формат обрабатываемого изображение отличен от заданного условия, то система вернет значение "0". Если условия не заданы — система вернет оцененное значение формата изображения.
Подробная информация и перечень выполняемых оценок и проверок описан в разделе "Проверка изображений".
Возможность выполнения проверки и оценки параметров изображений регулируется специальным параметром в файле лицензии.
Включение/отключение некоторых эстиматоров и детекторов#
По умолчанию сервис Remote SDK запускается со всеми включенными эстиматорами и детекторами. При необходимости можно отключить использование некоторых эстиматоров или детекторов при запуске контейнера Remote SDK. Отключение ненужных эстиматоров позволяет экономить оперативную память или память GPU, поскольку при старте сервиса Remote SDK выполняется проверка возможности выполнения указанных оценок и загрузка нейронных сетей в память.
При отключении эстиматора или детектора можно также удалить его нейронную сеть из контейнера Remote SDK.
Отключение эстиматоров или детекторов возможно с помощью передачи аргументов с названиями эстиматоров в команду запуска сервиса Remote SDK. Аргументы передаются в контейнер с помощью переменной "EXTEND_CMD".
Список доступных эстиматоров:
| Аргумент | Описание |
|---|---|
| --enable-all-estimators-by-default | включить все эстиматоры по умолчанию |
| --enable-human-detector | одновременный детектор тел и тел |
| --enable-face-detector | детектор лиц |
| --enable-body-detector | детектор тел |
| --enable-people-count-estimator | эстиматор количества людей |
| --enable-face-landmarks5-estimator | эстиматор 5 контрольных точек лица |
| --enable-face-landmarks68-estimator | эстиматор 68 контрольных точек лица |
| --enable-head-pose-estimator | эстиматор положения головы |
| --enable-liveness-estimator | эстиматор Liveness |
| --enable-deepfake-estimator | эстиматор Deepfake |
| --enable-fisheye-estimator | эстиматор бочкообразной дисторсии (эффекта FishEye) |
| --enable-face-detection-background-estimator | эстиматор фона изображения |
| --enable-face-warp-estimator | эстиматор биометрического образца лица |
| --enable-body-warp-estimator | эстиматор биометрического образца тела |
| --enable-quality-estimator | эстиматор качества изображения |
| --enable-image-color-type-estimator | эстиматор типа цвета по лицу |
| --enable-face-natural-light-estimator | эстиматор естественности освещения |
| --enable-eyes-estimator | эстиматор глаз |
| --enable-gaze-estimator | эстиматор направления взгляда |
| --enable-mouth-attributes-estimator | эстиматор атрибутов рта |
| --enable-emotions-estimator | эстиматор эмоций |
| --enable-mask-estimator | эстиматор маски |
| --enable-glasses-estimator | эстиматор очков |
| --enable-eyebrow-expression-estimator | эстиматор бровей |
| --enable-red-eyes-estimator | эстиматор красных глаз |
| --enable-headwear-estimator | эстиматор головного убора |
| --enable-basic-attributes-estimator | эстиматор базовых атрибутов |
| --enable-face-descriptor-estimator | эстиматор извлечения биометрического шаблона лица |
| --enable-body-descriptor-estimator | эстиматор извлечения биометрического шаблона тела |
| --enable-body-attributes-estimator | эстиматор атрибутов тел |
Можно явно указать какие эстиматоры и детекторы включены или выключены с помощью передачи соответствующих аргументов в переменную "EXTEND_CMD", или же включить (по умолчанию) или выключить их все с помощью аргумента enable-all-estimators-by-default. Можно выключить использование всех эстиматоров и детекторов, а затем включить определенные эстиматоры с помощью передачи соответствующих аргументов.
Пример команды запуска сервиса Remote SDK с использованием только детектора лиц и эстиматоров биометрического образца лица и эмоций.
docker run \
...
--env=EXTEND_CMD="--enable-all-estimators-by-default=0 --enable-face-detector=1 --enable-face-warp-estimator=1 --enable-emotions-estimator=1" \
...
Сервис Handlers#
Сервис Handlers используется для создания и хранения обработчиков и верификаторов.
Данные обработчиков и верификаторов хранятся в базе данных Handlers.
Отправка событий в сторонний сервис#
В LUNA PLATFORM доступна возможность отправки уведомлений через веб-сокеты или веб-хуки (HTTP). Для этого предназначена политика "callbacks".
Отправка уведомлений через веб-сокеты
Политика "callbacks" с параметром luna-ws-notification предоставляет механизм уведомлений, основанный на принципах веб-сокетов. Этот тип callback'a позволяет получать события через веб-сокеты от сервиса Sender, который взаимодействует с сервисом Handlers через механизм pub/sub по каналу Redis. Это обеспечивает прямое, мгновенное обновление данных, используя двусторонний канал связи между клиентом и сервером.
Преимущества:
- Прямое, мгновенное обновление данных по веб-сокетам.
- Эффективное использование открытого двустороннего канала.
- Низкая задержка в передаче уведомлений.
В предыдущих версиях LUNA PLATFORM использовалась политика "notification_policy". В настоящий момент она считается устаревшей и не рекомендуется к использованию. Основным преимуществом механизма callback'ов перед устаревшей "notification_policy" является возможность указания нескольких callback'ов с разными фильтрами в запросе на создание обработчика, в результате чего будет отправлено только одно событие.
См. подробную информацию в разделе "Сервис Sender".
Отправка уведомлений через веб-хуки
Политика "callbacks" с параметром http предоставляет механизм уведомлений, основанный на принципах веб-хуков для HTTP. Они обеспечивают асинхронное взаимодействие между системами, позволяя внешним сервисам реагировать на появление событий. В рамках этой политики можно задать конкретные параметры, такие как тип протокола, адрес внешней системы, параметры и данные авторизации.
Преимущества:
- Более гибкий механизм настройки уведомлений.
- Простая интеграция с различными внешними системами.
- Использует привычные HTTP-протоколы и конфигурации.
Сервис Image Store#
Сервис Image Store хранит следующие данные:
- Биометрические образцы лица и тела. БО сохраняются в Image Store сервисом Remote SDK или с помощью запросов "samples" > "detect faces" и "samples" > "save face/body sample".
- Отчеты о задачах. Отчеты сохраняются "рабочими процессами" сервиса Tasks.
- Любые объекты, загружаемые с помощью запроса "create objects".
- Информацию о кластеризации.
Сервис Image Store имеет возможность сохранять данные либо на локальном накопителе, либо в S3-подобном облачном хранилище (например, Amazon S3 и др.).
Описание бакетов#
Данные хранятся в специальных директориях, называемых бакетами. У каждого бакета есть уникальное имя. Имена бакетов должны быть заданы строчными буквами.
В LP используются следующие бакеты:
- "visionlabs-samples" — хранит БО лиц.
- "visionlabs-body-samples" — хранит БО тел.
- "visionlabs-image-origin" — хранит исходные изображения.
- "visionlabs-objects" — хранит объекты.
- "task-result" — хранит результаты, полученные после обработки задач с помощью сервиса Tasks.
- "portraits" — необходим для использования сервиса Backport 3. В бакете хранятся портреты (см. описание портретов в документации LUNA PLATFORM 3).
Процедура создания бакетов описана в руководстве по установке LP 5 в разделе "Создание бакетов".
После запуска контейнера Image Store и команд для создания контейнеров, бакеты сохраняются в локальное хранилище или S3.
По умолчанию локальные файлы хранятся в каталоге "/var/lib/luna/current/example-docker/image_store" на сервере. Они сохраняются в каталоге "/srv/local_storage/" в контейнере Image Store.
Бакет содержит каталоги с биометрическими образцами или другими данными. Названия каталогов соответствуют первым четырем буквам идентификатора БО. Все образцы распределяются по этим каталогам в соответствии с первыми четырьмя символами их идентификаторов.
Рядом с объектом бакета расположен файл «*.meta.json», содержащий «account_id», используемый при выполнении запроса. Если объект бакета не является биометрическим образцом (например, объект бакета — JSON-файл в бакете «task-result»), то в данном файле также будет указан «Content-Type».
Пример структуры директорий бакетов "visionlabs-samples", "task-result" и "visionlabs-bodies-samples" приведен ниже.
./local_storage/visionlabs-samples/8f4f/
8f4f0070-c464-460b-sf78-fac234df32e9.jpg
8f4f0070-c464-460b-sf78-fac234df32e9.meta.json
8f4f1253-d542-621b-9rf7-ha52111hm5s0.jpg
8f4f1253-d542-621b-9rf7-ha52111hm5s0.meta.json
./local_storage/task-result/1b03/
1b0359af-ecd8-4712-8fc0-08401612d39b
1b0359af-ecd8-4712-8fc0-08401612d39b.meta.json
./local_storage/visionlabs-bodies-samples/6e98/
6e987e9c-1c9c-4139-9ef4-4a78b8ab6eb6.jpg
6e987e9c-1c9c-4139-9ef4-4a78b8ab6eb6.meta.json
При хранении большого количества биометрических образцов может потребоваться значительный объем памяти. Один биометрический образец занимает около 30 Кбайт дискового пространства.
Также рекомендуется создавать резервные копии БО. БО используются при изменении версии нейросети или при необходимости восстановить базу данных лиц.
Использование S3-подобного хранилища#
Для включения использования S3-подобного хранилища необходимо выполнить следующие действия:
- убедиться, что ключ доступа имеет достаточные полномочия для доступа к бакетам S3-подобного хранилища;
- запустить сервис Image Store (см. раздел "Image Store" в руководстве по установке);
- задать значение "S3" для настройки "storage_type" настроек сервиса Image Store;
- заполнить настройки для соединения с S3-подобным хранилищем (адрес, ключи Access Key и Secret Key и др.) в группе параметров "S3" настроек сервиса Image Store;
- запустить скрипт по созданию бакетов
lis_bucket_create.py(см. раздел "Создание бакетов" в руководстве по установке)
При необходимости можно отключить проверку SSL-сертификата с помощью настройки "verify_ssl" в группе параметров "S3" настроек сервиса Image Store. Это позволяет использовать самоподписанный SSL-сертификат.
TTL объектов#
Можно задать время жизни (TTL) для объектов в бакетах (как локальных, так и S3). Под объектами понимаются:
- биометрические образцы лиц или тел
- изображения или объекты, создаваемые в ресурсах "/images" или "/objects"
- исходные изображения
- результаты задач
TTL для объектов рассчитывается относительно формата времени GMT.
TTL для объектов задается в днях следующими способами:
- во время создания бакета для всех объектов сразу (основная политика TTL бакета)
- после создания бакета для конкретных объектов с помощью запросов к соответствующим ресурсам
Количество дней выбирается из списка в соответствующих запросах (см. ниже).
Кроме количества дней параметр может принимать значение "-1", означающее, что нужно хранить объекты бессрочно.
Настройка основной политики TTL бакета#
Основную политику TTL бакета можно настроить следующими способами:
- с помощью флага
--bucket-ttlдля скриптаlis_bucket_create.py. Например,python3 ./base_scripts/lis_bucket_create.py -ii --bucket-ttl=2. - с помощью запроса к сервису Image Store. Например,
curl -X POST http://127.0.0.1:5020/1/buckets?bucket=visionlabs-samples?ttl=2.
Настройка TTL для конкретных объектов#
TTL для конкретных объектов можно настроить с помощью параметра "ttl" в следующих местах:
- в политиках "storage_policy" > "face_sample_policy", "body_sample_policy" и "image_origin_policy" обработчика
- в запросах "create object", "create images" и "save sample"
- в запросах на создание задач или расписания в поле "result_storage_policy"
Если параметр "ttl" не задан, то будет применена основная политика бакета, в котором находится объект (cм. выше).
Добавление TTL к существующим объектам#
Добавить TTL для существующего конкретного объекта можно с помощью PUT-запросов к ресурсам /objects, /images, /samples/{sample_type} сервиса Image Store. Добавить TTL результатов задач к уже созданным и выполненным задачам невозможно. Добавить TTL результатов задач к уже созданному расписанию можно с помощью запроса "replace tasks schedule". Для созданных или запущенных на момент запроса задач TTL результатов задач применен не будет.
Добавить TTL к основной политике бакета (ко всем существующим объектам в бакете) можно с помощью PUT-запроса к ресурсу /buckets сервиса Image Store.
Для бакета, расположенного в S3, необходимо выполнить миграцию с помощью скрипта "base_scripts/migrate_ttl_settings" сервиса Image Store. Это связано с тем, что для TTL объектов в S3 применяется через фильтры, связанные с тегами. Команда выполнения миграции бакетов в S3 приведена в руководстве по установке. См. подробную информацию о миграции бакетов S3 в разделе "Миграция для добавления TTL к объектам в S3".
Поддерживаемые облачные провайдеры#
Поддерживаются облачные провайдеры Amazon S3, облачное хранилище Яндекса и MinIO.
Миграция для добавления TTL к объектам в S3#
Настройка жизненного цикла для объектов в S3 применяется через фильтры, связанные с тегами (см. официальную документацию). Это предполагает, что объекты имеют тег с ограниченным набором значений, а бакеты имеют набор правил, основанных на значении этого тега.
Для добавления тегов и правил необходимо выполнить миграцию. Миграция строго необходима для полного применения настройки жизненного цикла по следующим причинам:
- бакеты без правил не будут удалять объекты, даже если пользователь указывает время жизни для конкретного объекта,
- объекты без тегов никогда не будут удалены, даже если пользователь указывает время жизни бакета.
Необходимо добавить следующие теги и правила:
- для поддержки TTL для бакетов необходимо добавить тег
vl-expireсо значением по умолчанию для всех существующих объектов. - для поддержки TTL для конкретных объектов необходимо добавить набор или связанные с TTL правила жизненного цикла для существующих сегментов:
{
"ID": "vl-expire-<ttl>",
"Expiration": {
"Days": <ttl>,
},
"Filter": {"Tag": {"Key": "vl-expire", "Value": <ttl>}},
"Status": "Enabled",
}
Поддерживается набор определенных значений тегов, связанных с TTL объекта: 1, 2, 3, 4, 5, 6, 7, 14, 30, 60, 90, 180, 365.
Процесс выполнения миграции состоит из двух этапов:
- настройка жизненного цикла бакета, расширенная набором правил жизненного цикла, связанных с TTL.
- присвоение каждому объекту в бакете тега
vl-expire, если он еще не обладает таковым.
Присвоение тега для каждого объекта при необходимости можно пропустить с помощью аргумента -update-tags=0.
См. примеры команд для выполнения миграции в руководстве по обновлению.
Проблемы с разрешениями
По умолчанию все ресурсы S3, включая бакеты, объекты и настройку TTL, являются приватными. При необходимости правила и теги по умолчанию могут быть созданы владельцем ресурса вручную одним из применимых методов. Подробности см. в официальной документации S3.
Полезные ссылки на официальную документацию:
- Creating a lifecycle configuration
- Put lifecycle configuration
- Managing object tags
- Expiring objects
Окончание TTL#
Когда TTL объекта подходит к концу, то он помечается для удаления. Для локальных бакетов выполняется задача очистки 1 раз в день (в 01:00 утра). Для бакетов S3 используются внутренние правила конфигурации TTL. Чтобы предотвратить конфликты или дублирование задач очистки при задействовании нескольких экземпляров или рабочих процессов, реализован механизм блокировки. Это гарантирует, что за выполнение процесса очистки локального хранилища отвечает только один экземпляр или рабочий процесс.
Между датой истечения срока действия и датой фактического удаления объекта может возникнуть задержка. Как для локального хранилища, так и для S3.
Поиск истекающих объектов#
Чтобы узнать, когда срок действия объекта истекает, можно использовать запросы с методами HEAD к ресурсам /objects и /images. Эти запросы возвращают заголовки ответов X-Luna-Expiry-Date, в которых указана дата, когда объект больше не подлежит сохранению.
Внешние биометрические образцы#
В Image Store можно отправить внешний биометрический образец. Внешний биометрический образец можно получить с помощью стороннего программного обеспечения или программного обеспечения VisionLabs (например, FaceStream).
См. запрос POST на ресурсе "/samples/{sample_type}" в "APIReferenceManual.html" для получения дополнительной информации.
Внешний БО должен соответствовать определенным стандартам, чтобы LP могла его обработать.
БО, полученные с помощью программного обеспечения VisionLabs, удовлетворяют этому требованию.
При использовании стороннего программного обеспечения не гарантируется, что результат обработки внешнего БО будет таким же, как и для образца VisionLabs. БО может быть низкого качества (слишком темный, размытый и т.д.). В результате низкого качества можно получить неверные результаты обработки изображения.
Рекомендуется проконсультироваться с представителями VisionLabs перед использованием внешних БО.
Сервис Accounts#
Сервис Accounts предназначен для:
- Создания, управления и хранения аккаунтов
- Создания, управления и хранения токенов и их разрешений
- Верификации аккаунтов и токенов
См. раздел "Аккаунты, токены и способы авторизации" для более подробной информации о системе авторизации в LUNA PLATFORM 5.
Все создаваемые аккаунты, токены и их разрешения сохраняются БД сервиса Accounts.
Алгоритмы JWT-токенов#
Механизм аутентификации JWT (JSON Web Tokens) поддерживает различные алгоритмы для подписи токенов. В этом разделе описывается используемый по умолчанию алгоритм и необходимые шаги для использования альтернативного алгоритма.
Алгоритм по умолчанию#
По умолчанию сервис использует алгоритм HS256 для подписи JWT-токенов. При необходимости можно использования асимметричного криптографического шифрования, вы можете использовать алгоритм ES256.
Использование алгоритма ES256#
Чтобы использовать алгоритм ES256, следуйте этим шагам:
-
Сгенерируйте закрытый ключ ECDSA
Сначала нужно сгенерировать закрытый ключ ECDSA, используя кривую
prime256v1. Это можно сделать с помощью инструментов командной строки, таких как OpenSSL.Пример команды:
openssl ecparam -genkey -name prime256v1 -out ec_private.pemВы также можете сгенерировать ключ, защищенный паролем, например:
openssl ecparam -genkey -name prime256v1 | openssl ec -aes256 -out ec_private_enc.pem -
Закодируйте закрытый ключ в формат Base64
После генерации закрытого ключа закодируйте его в формат Base64. Это можно сделать с помощью инструментов, доступных в большинстве операционных систем.
Пример команды:
base64 -w0 ecdsa_private.pem > ecdsa_private_base64 -
Установите переменную окружения
Закодированный закрытый ключ должен быть указан в переменной окружения
ACCOUNTS_JWT_ECDSA_KEYпри старте контейнера. Это позволяет сервису использовать ключ для подписи JWT-токенов алгоритмом ES256.Кроме того, если ваш закрытый ключ защищен паролем, вы можете указать пароль в переменной среды
ACCOUNTS_JWT_ECDSA_KEY_PASSWORD.Пример команды запуска контейнера с передачей переменных окружения:
docker run \ --env=CONFIGURATOR_HOST=127.0.0.1 \ --env=ACCOUNTS_JWT_ECDSA_KEY=jwt_ecdsa_key \ --env=ACCOUNTS_JWT_ECDSA_KEY_PASSWORD=ecdsa_key_password \ ...
Следуя этим шагам, сервис сможет подписывать JWT-токены с использованием алгоритма ES256, обеспечивая повышенную безопасность с помощью асимметричной криптографии.
Влияние изменения типа алгоритма#
Переключение алгоритма подписи с HS256 на ES256 (или наоборот) оказывает значительное влияние на проверку токенов. Все существующие токены, подписанные предыдущим алгоритмом, станут недействительными после внесения изменений. Это происходит потому, что механизм проверки подписи токена ожидает, что структура и криптографическая база токена будут соответствовать новоуказанному алгоритму.
Сервис Faces#
Сервис Faces предназначен для:
- Создания временных атрибутов;
- Создания лиц;
- Создания списков;
- Прикрепления лиц к спискам;
- Управления общей базой данных, в которой хранятся лица с прикрепленными данными и списки;
- Получения информации о существующих лицах и списках.
Сервисы сравнения#
Python Matcher позволяет осуществлять:
- Сравнение в соответствии с заданными фильтрами. Такое сравнение выполняется непосредственно в базе данных лиц или событий. Сравнение по БД целесообразно, когда установлено несколько фильтров.
- Сравнение по спискам. В этом случае рекомендуется сохранять биометрические шаблоны в кеше Python Matcher.
Python Matcher Proxy используется для маршрутизации запросов к сервисам Python Matcher и плагинам сравнения.
Python Matcher#
Python Matcher использует базу данных Faces для фильтрации и сравнения, когда лица заданы как кандидаты для сравнения и для них указаны фильтры. Эта функция всегда включена для Python Matcher.
Python Matcher использует базу данных Events для фильтрации и сравнения, когда события заданы как кандидаты для сравнения и для них указаны фильтры. Сравнение с использованием базы данных Events является необязательным и не используется, если не используется сервис Events.
Для сравнения по БД требуется функция сравнения VLMatch. Она должна быть зарегистрирована для БД Faces и БД Events. Функция использует библиотеку, которая должна быть скомпилирована для вашей текущей версии БД. Информацию об этом можно найти в руководстве по установке в разделах "Компиляция библиотеки VLMatch", "Создание функции VLMatch для БД Faces" и "Создание функции VLMatch для БД Events".
Сервис Python Matcher дополнительно использует "рабочие процессы", обрабатывающие запросы.
Python Matcher Proxy#
Сервис API отправляет запросы на прокси-сервер Python Matcher, если его использование включено в настройках сервиса API. Затем сервис Python Matcher Proxy перенаправляет запросы к сервису Python Matcher или на плагины сравнения (если они используются).
Если плагины сравнения не используются, то сервис перенаправляет запросы только к сервису Python Matcher. Таким образом, не нужно использовать Python Matcher Proxy если не собираетесь использовать плагины сравнения. См. описание работы плагинов сравнения в разделе "Плагины сравнения".
Кеширование списков#
Когда лица заданы как кандидаты для сравнения и идентификаторы списков для них указаны в качестве фильтров, Python Matcher выполняет сравнение по спискам.
По умолчанию при запуске сервиса Python Matcher все биометрические шаблоны во всех списках кешируются в его память.
Управление кешированием осуществляется за счет группы параметров "DESCRIPTORS_CACHE".
Сервис Python Matcher не будет запущен, пока не загрузит в кеш все доступные биометрические шаблоны.
При выполнении запроса на сравнение по спискам, сервис Python Matcher автоматически добавляет его в очередь, откуда его забирает "рабочий процесс" и направляет в сущность Cached Matcher для выполнения сравнения по кешированным данным.
После выполнения сравнения, "рабочий процесс" забирает результаты и возвращает их сервису Python Matcher и пользователю.
Такое кеширование позволяет значительно увеличить производительность сравнения.
При необходимости можно обрабатывать только конкретные списки с помощью настройки "cached_data > faces_lists > include" или исключать списки с помощью настройки "cached_data > faces_lists > exclude". Последняя особенно полезна при работе с модулем LUNA Index Module для реализации логики обработки части списков с помощью Python Matcher, а части с помощью LIM Indexed Matcher.
См. подробную информацию о LIM в разделе "Сравнение большого набора биометрических шаблонов".
Кеш «рабочих процессов»#
Когда для сервиса Python Matcher запускается несколько "рабочих процессов", каждый из "рабочих процессов" использует один и тот же кеш биометрических шаблонов.
Его изменение может как ускорить, так и замедлить работу сервиса. Если нужно убедиться, что кеш хранится в каждом из процессов Python Matcher, необходимо запустить каждый из экземпляров сервера отдельно.
Сервис Events#
Сервис Events предназначен для:
- Хранения всех созданных событий в базе данных Events.
- Выдачи всех событий в соответствии с фильтрами.
- Сбора статистики по всем существующим событиям в соответствии с заданной агрегацией и частотой/периодичностью.
- Хранения биометрических шаблонов, созданных для событий.
Поскольку событие представляет собой отчет, нельзя изменить уже существующие события.
Сервис Events должен быть активирован в файле конфигурации сервиса API. В противном случае события не будут сохраняться в базе данных.
База данных для сервиса Events#
В качестве базы данных для сервиса Events используется PostgreSQL.
На скорость обработки запросов в первую очередь влияют:
- количество событий в базе данных
- отсутствие индексов для PostgreSQL
PostgreSQL показывает допустимую скорость обработки запросов, если количество событий составляет от 1 000 000 до 10 000 000. Если количество событий превышает 10 000 000, запрос к PostgreSQL может завершиться неудачей.
Скорость обработки запросов статистики к СУБД PostgreSQL можно увеличить, настроив базу данных и создав индексы.
Географическое положение#
При создании события можно добавить географическое положение.
Географического положение представлено в виде JSON с GPS-координатами географической точки:
- долгота – географическая долгота в градусах
- широта – географическая широта в градусах
Географическое положение указывается в параметре "location" тела запроса на создание события. См. запрос "create new events" в спецификации OpenAPI сервиса Events.
Можно использовать фильтр географического положения, чтобы получить все события, которые произошли в соответствующей области.
Фильтр географического положения#
Фильтр географического положения – это ограничивающий прямоугольник, заданный координатами его центра (начало) и некоторой дельтой.
Он задается с использованием следующих параметров:
- origin_longitude
- origin_latitude
- longitude_delta
- latitude_delta
Фильтр можно использовать при получении событий, получении статистики по событиям и выполнении сравнения событий.
Фильтр географического положения считается правильно заданным, если:
- заданы и origin_longitude, и origin_latitude.
- не заданы ни origin_longitude, ни origin_latitude, ни longitude_delta или latitude_delta.
Если заданы параметры origin_longitude и origin_latitude, а параметры longitude_delta не заданы – применяется значение по умолчанию (см. значение по умолчанию в документации OpenAPI).
Прочтите следующие рекомендации перед использованием фильтров географического положения.
Общие рекомендации и ограничения для фильтров географического положения:
- Не нужно создавать фильтры с общей точкой или границей на Международной линии перемены дат (IDL), Северном или Южном полюсе. Они не полностью поддерживаются из-за особенностей пространственного индекса базы данных. Результат фильтрации может быть непредсказуемым;
- Фильтры географического положения с границами длиной более 180 градусов не допускаются;
- Настоятельно рекомендуется использовать фильтр географического положения только в масштабах города. Если указана большая область, результаты фильтрации на границах области могут быть неожиданными из-за пространственных особенностей.
- Не нужно создавать фильтр слишком протяжённый по долготе или широте. Рекомендуется устанавливать значения дельт близкими друг к другу.
Последние две рекомендации приводятся из-за пространственных особенностей фильтра. В соответствии с этими функциями, если установлены большие значения одной или двух дельт, результат может отличаться от предполагаемого, несмотря на то, что он будет правильным. См. подробную информацию в разделе "Особенности фильтра".
Эффективность фильтра#
Эффективность фильтра географического положения зависит от типа пространственных данных, используемых для сохранения географического положения события в базе данных.
Поддерживаются два типа пространственных данных:
- GEOMETRY (геометрический): пространственный объект с координатами, выраженными в виде пар (долгота, широта), определенных в декартовой плоскости. При всех расчетах используются декартовы координаты.
- GEOGRAPHY (географический): пространственный объект с координатами, выраженными в виде пар (долгота, широта), определенных как на поверхности идеальной сферы, или пространственный объект в системе координат WGS84.
Подробное описание см. в разделе геометрия в сравнении с географией.
Фильтр географического положения на основе функции PostGIS ST_Covers, поддерживается как для геометрического, так и для географического типа.
Особенности фильтра#
Фильтр географического положения имеет некоторые особенности, обусловленные PostGIS.
Если при использовании географического типа фильтр географического положения покрывает большую часть поверхности планеты, результат фильтрации может быть неожиданным, но географически правильным из-за некоторых пространственных особенностей.
Например, в базу данных добавлено событие со следующей географической позицией:
{
"longitude": 16.79,
"latitude": 64.92,
}
Далее применяется фильтр географического положения и производится попытка найти нужную точку на карте. В результате фильтр получается слишком большим по долготе:
{
"origin_longitude": 16.79,
"origin_latitude": 64.92,
"longitude_delta": 2,
"latitude_delta": 0.01,
}
Таким образом, этот фильтр не выдает ожидаемое событие. Событие фильтруется по пространственным особенностям. В данном примере показан случай, когда точка находится за пределами фильтра.

Необходимо учитывать эту особенность при создании фильтра.
Подробная информация приведена в разделе Geography сайта Postgis.
Создание событий#
События создаются с помощью обработчиков. Обработчики хранятся в базе данных Handlers. Необходимо указать требуемый идентификатор обработчика в запросе на создание события. Все данные, хранящиеся в событии, будут получены в соответствии с параметрами обработчика.
Необходимо выполнить два отдельных запроса на создание события.
Первый запрос создает обработчик. Обработчик содержит политики, которые определяют, как обрабатывается изображение, и, следовательно, определяют сервисы LP, используемые для обработки.
Второй запрос создает новые события с использованием существующего обработчика. Событие создается для каждого обработанного изображения.
Можно указать следующие дополнительные данные для каждого запроса на создание события:
- внешний идентификатор (для созданных лиц),
- пользовательские данные (для созданных лиц),
- источник (для созданных событий),
- теги (для созданных событий).
Обработчик обрабатывает политику за политикой. Все данные из запроса обрабатываются политикой перед переходом к следующей политике. Сначала политика "detect" выполняется для всех изображений из запроса, затем применяется политика "multiface", затем выполняется политика "extract" для всех полученных биометрических образцов и т.д. Более подробную информацию об обработчиках см. в разделе "Описание обработчиков".
Общие события#
В случае, если необходимо сохранить событие с какой-либо пользовательской структурой, сгенерированной видеоаналитикой, плагином или каким-либо клиентским приложением, следует использовать механизм общих событий. Размер общего события не должен превышать лимит в 2 МБ.
Поскольку общие события имеют свободную структуру, они должны быть разделимы по типу (параметр "event_type"), который следует указать при сохранении события.
При сохранении общего события также следует предоставить некоторую общую информацию (например, время создания события, время окончания события, аккаунт, которому принадлежит событие).
Несмотря на то, что структура общего события свободна, она может содержать определенный набор полей, специфичных для LUNA PLATFORM (например, местоположение, идентификатор потока, идентификатор трека), поиск по которым может выполняться более эффективно за счет оптимизации хранения этих данных в базе данных Events.
Пользователю предоставляется:
- Возможность сохранять события свободной структуры.
- Возможность получать сохраненные события.
- Возможность фильтровать по общей информации общего события (например,
event_type,event_create_time,event_end_time,account_id). - Возможность фильтровать по необязательным полям общего события, присущим LUNA PLATFORM (например,
location,stream_id,track_id). - Возможность фильтровать по полям содержимого пользовательской структуры.
Пользователь обязуется:
- Поддерживать данные в соответствии с заданными схемами. В случае несоответствия PostgreSQL не позволит вставить строку с типом, который не может быть добавлен в существующий индекс (если таковой имеется).
- Мигрировать данные при необходимости.
- Строить частичные индексы в соответствии с типами событий.
- Указывать тип данных при выполнении запроса (по умолчанию все значения предполагаются строками).
- Обращать внимание на имена полей пользовательской структуры. Поля, по которым будет выполняться фильтрация, не должны содержать зарезервированных ключевых слов, таких как
:int, двойных подчеркиваний, специальных символов и т. д.
См. подробную информацию о построениии индексов и решению различных проблем с общими событиями в руководстве разработчика сервиса Events.
Способ сохранения общих событий#
Сохранить общее событие можно с помощью запроса "create new general events" к сервису Events.
Соответственно, если пользователь пишет собественный плагин или приложение, то он должен отправлять данные в вышеописанный эндпоинт.
Поиск общих событий#
Для поиска событий предназначены следующие запросы:
В данные запросы можно передать фильтры. Существует несколько соглашений для указания фильтров:
- Для навигации по вложенным объектам используйте точку (
.), например,event.user_info.temperature. - Для указания оператора сравнения используйте суффикс с двойным подчеркиванием (
__eq,__like,__in,__gt,__ltи т. д.), например,event.user_info.temperature__gte. - Для указания типа данных используйте суффикс с двоеточием (
:string,:integer,:numeric), например,event.user_info.temperature__gte:numeric.
Также можно получить статистику по общим событиям с помощью запроса "get statistics on general events".
Метаинформация события#
В случае, если вместе с событием необходимо сохранить какие-либо дополнительные данные, следует использовать поле "meta". Поле "meta" хранит в себе данные формата JSON. Общий размер данных, хранимых в поле "meta" для одного события не может превышать 2 Мб. Предполагается, что с помощью данного функционала пользователь создаст свою модель данных (структуру события) и будет использовать её для хранения необходимых данных.
Обратите внимание, что в поле "meta" нельзя указывать имена полей с пробелами.
Данные в поле "meta" можно записывать следующими способами:
- в теле запроса "generate events" с типом содержимого
application/jsonилиmultipart/form-data - в теле запроса "save event"
- с помощью пользовательского плагина или клиентского приложения.
В теле запроса "generate events" доступна возможность задать поле "meta" как для конкретных изображений, так и для всех изображений сразу (взаимная метаинформация). Для запросов с включенной агрегацией для агрегированного события будет использоваться только взаимная метаинформация, а метаинформация для конкретных изображений будет игнорироваться. См. подробную информацию в теле запроса "generate events" в спецификации OpenAPI.
Пример записи поля "meta":
{
"meta": {
"user_info": {
"temperature": 36.6
}
}
}
Для того, чтобы хранить несколько структур, необходимо явно разделять их, чтобы избежать пересечения полей. Например, следующим образом:
{
"struct1": {
...
},
"struct2": {
...
}
}
Поиск по полю "meta"#
Содержимое поля "meta" можно получить с помощью соответствующего фильтра в запросе "get events".
Фильтр нужно вводить с помощью определенного синтаксиса — meta.<path.to.field>__<operator>:<type>, где:
meta.— указание, что идет обращение к полю "meta" базы данных Events;<path.to.field>— путь до объекта. Для навигации по вложенным объектам используется точка (.). Например, в строке{"user_info":{"temperature":"36.6"}}для обращения к объектуtemperatureнужно использовать следующий фильтрmeta.user_info.temperature__<operator>— один из следующих операторов —eq(по умолчанию),neq,like,nlike,in,nin,gt,gte,lt,lte. Например,meta.user_info.temperature__gte;:type— один из следующих типов данных —string,integer,numeric. Например,meta.user_info.temperature__gte:numeric.
Для каждого оператора доступно использование определенных типов данных. См. таблицу зависимости операторов от типов данных в спецификации OpenAPI.
При необходимости можно построить индекс для улучшения поиска. См. подробную информацию о построении индекса в руководстве разработчика сервиса Events.
Важные замечания#
При работе с полем "meta" необходимо помнить следующее:
- нужно сохранять данные в соответствии с заданными схемами; в случае несоответствия, PostgreSQL не позволит вставить строку с типом, который не может быть добавлен в существующий индекс (если таковой имеется);
- при необходимости можно мигрировать данные;
- при необходимости можно построить индекс;
- нужно указывать тип данных при выполнении запроса (по умолчанию предполагается, что все значения являются строками);
- нужно обращать внимание на названия полей; поля, по которым производится фильтрация, не должны содержать зарезервированных ключевых слов, таких как
:int, двойные подчеркивания, специальные символы и так далее.
Сервис Sender#
Сервис Sender – это дополнительный сервис, который используется для отправки событий через веб-сокеты. Данный сервис коммуницирует с сервисом Handlers (в котором создаются события) через механизм pub/sub по каналу БД Redis.
При необходимости можно отправлять уведомления по HTTP-протоколу. См. раздел "Отправка событий в сторонний сервис" для более подробной информации.
События создаются на основе обработчиков. Для получения уведомлений необходимо наличие включенной политики "callbacks" с параметром "luna-ws-notification". У данной политики есть фильтры, позволяющие отправлять уведомления только при определенных условиях, например, отправлять только при большом сходстве кандидата с эталоном (параметр "similarity__lte").
В предыдущих версиях LUNA PLATFORM использовалась политика "notification_policy". В настоящий момент она считается устаревшей и не рекомендуется к использованию. Основным преимуществом механизма callback'ов перед устаревшей "notification_policy" является возможность указания нескольких callback'ов с разными фильтрами в запросе на создание обработчика, в результате чего будет отправлено только одно событие.
Необходимо настроить подключение к веб-сокетам по специальному запросу. Рекомендуется создавать соединение через веб-сокеты, используя ресурс "/ws" сервиса API. В запросе можно указать фильтры (параметры запроса), т.е. можно настроить сервис Sender так, чтобы получать только определенные события. См. спецификацию OpenAPI для получения подробной информации о конфигурации создания подключения к веб-сокету.
Также можно настроить веб-сокеты напрямую через сервис Sender (ресурс "/ws" сервиса Sender). Этот способ можно использовать для снижения нагрузки на сервис API.
После создания события, оно может:
-
сохраниться в базе данных сервиса Events. Для сохранения события необходимо включить сервис Events;
-
быть выдано в ответ без сохранения в базе данных.
В обоих случаях событие отправляется через канал БД Redis в сервис Sender.
БД Redis в данном случае выступает в качестве связи сервисов Sender и Handlers и не хранит передаваемые события.
Сервис Sender не зависит от сервиса Events. События могут отправляться в сервис Sender, даже если сервис Events отключен.
Общий процесс работы выглядит следующим образом:
Создание обработчиков и указание фильтров для отправки уведомлений
- Пользователь отправляет запрос "create handler" в сервис API, где включает политику "callbacks" и задает фильтры, в соответствии с которыми будет выполняться отправка событий в сервис Sender;
- Сервис API отправляет запрос в сервис Handlers;
- Сервис Handlers отправляет ответ в сервис API;
- Сервис API отправляет "handler_id" пользователю.
Пользователь сохраняет идентификатор "handler_id", который необходим для создания событий.

Активация подписки на события и фильтрация их отправки
- Пользователь или приложение отправляет запрос "ws handshake" в сервис API и задает фильтры, благодаря которым можно будет фильтровать полученные данные от сервиса Handlers;
- Сервис API отправляет запрос в сервис Sender;
- Сервис Sender устанавливает постоянное соединение через веб-сокеты с пользовательским приложением.
- Теперь при генерации события, оно будет автоматически перенаправляться в сервис Sender (см. ниже) в соответствии с указанными фильтрами.
Теперь при генерации события, оно будет автоматически перенаправляться в сервис Sender (см. ниже) в соответствии с указанными фильтрами.
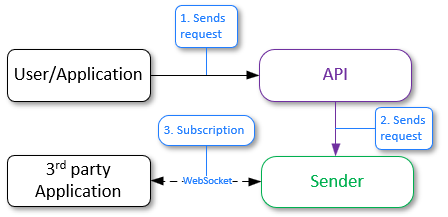
Генерация событий и отправка в Sender
- Пользователь или приложение отправляет запрос "generate events" в сервис API;
- Сервис API отправляет запрос в сервис Handlers;
- Сервис Handlers отправляет запрос в соответствующие сервисы LP;
- Сервисы LP обрабатывают запросы и отправляют результаты. Создаются новые события;
- Сервис Handlers отправляет событие в базу данных Redis, используя модель pub/sub. В Redis есть канал, на который подписан сервис Sender, и он ожидает получение сообщений из этого канала;
- Redis отправляет полученные события в сервис Sender по каналу;
- Для получения событий сторонние приложения должны быть подписаны на сервис Sender через веб-сокеты. Если есть подписанное стороннее приложение, Sender отправляет ему события в соответствии с указанными фильтрами.
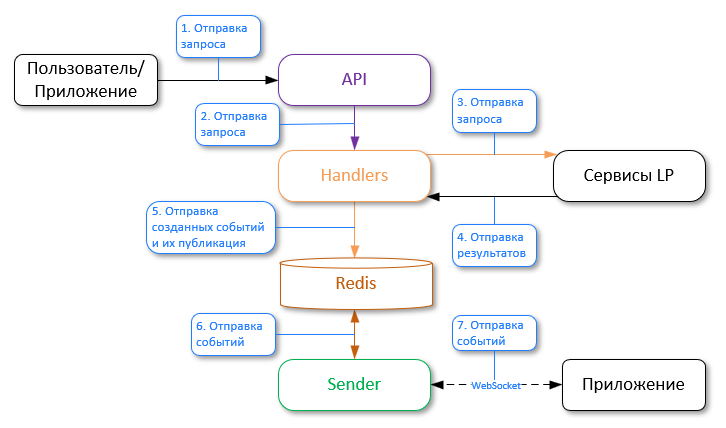
См. документацию OpenAPI для получения информации о структуре JSON, выдаваемой сервисом Sender.
Сервис Tasks#
Сервис Tasks предназначен для выполнения длительных задач.
Общая информация о задачах#
Обработка задач занимает значительное время, поэтому после создания задачи в ответе возвращается идентификатор задачи.
После завершения обработки задачи можно получить результаты задачи с помощью запроса "task " > "get task result". Необходимо указать идентификатор задачи, чтобы получить ее результаты.
Примеры результатов обработки задач можно найти в разделе ответа на запрос "task " > "get task result". Необходимо выбрать тип задачи в разделе Response samples документации.
Перед отправкой запроса на получение результата необходимо убедиться в том, что задача выполнена:
- Можно проверить статус задачи, указав идентификатор задачи в запросе "tasks" > "get task". Существуют следующие статусы задач:
| статус задач | значение |
|---|---|
| в ожидании (pending) | 0 |
| обрабатывается (in progress) | 1 |
| отменена (cancelled) | 2 |
| выполнена с ошибкой (failed) | 3 |
| сбор результатов (collect results) | 4 |
| выполнена (done) | 5 |
- Можно получить информацию обо всех задачах с помощью запроса "tasks" > "get tasks". Можно установить фильтр, чтобы получать информацию только по интересующим задачам.
Запросы на выполнение задач доступны для различных сервисов. В данном документе рассмотрены примеры создания задач с помощью сервиса API, Admin и пользовательского интерфейса Admin. Для подробной информации о создании задач с помощью прямых запросов к сервису Tasks см. в спецификации сервиса Tasks.
Задача Clustering#
В результате выполнения задачи создается кластер с объектами, выбранными в соответствии с заданными фильтрами для лиц или событий. Объекты, соответствующие всем фильтрам, добавляются в кластер. Имеющиеся фильтры зависят от типа объекта: события или лица.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
Можно использовать задачу создания отчета для получения отчета об объектах, добавленных в кластеры.
Кластеризация выполняется в несколько этапов:
-
объекты с биометрическими шаблонами собираются в соответствии с предоставленными фильтрами
-
каждый объект сопоставляется со всеми остальными объектами
-
создаются кластеры в виде групп "связанных компонентов" из графа схожести.
Здесь "связанные" означает, что схожесть превышает указанный порог или значение по умолчанию "DEFAULT_CLUSTERING_THRESHOLD" из настроек.
- при необходимости загружаются существующие изображения, соответствующие каждому объекту: аватар для лица, первый биометрический образец для события.
В результате выполнения задачи выдается массив кластеров. Кластер содержит идентификаторы объектов (лиц или событий), схожесть которых превышает заданный порог. Можно использовать информацию для дальнейшего анализа данных.
{
"errors": [],
"result": {
"clusters": [
[
"6c721b90-f5a0-409a-ab70-bc339a70184c"
],
[
"8bc6e8df-410b-4065-b592-abc5f0432a1c"
],
[
"e4e3fc66-53b4-448c-9c88-f430c00cb7ea"
],
[
"02a3a1c4-93d7-4b69-99ec-21d5ef23852e",
"144244cb-e10e-478c-bdac-18cd2eb27ee6",
"1f4cdbcb-7b1e-40cc-873b-3ff7fa6a6cf0"
]
],
"total_objects": 6,
"total_clusters": 4
}
}
Результат задачи Clustering может также содержать информацию об ошибках, возникших при обработке объектов.
Для такой задачи можно создать расписание.
Задача Reporter#
В результате выполнения этой задачи создается отчет по задаче Clustering. Можно выбрать данные, которые необходимо добавить в отчет. Отчет предоставляется в формате CSV.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
Можно указать идентификатор задачи Clustering и столбцы, которые необходимо добавить в отчет. Выбранные столбцы соответствуют основным полям событий и лиц.
Необходимо убедиться в том, что выбранные столбцы соответствуют объектам, выбранным при выполнении задачи Clustering.
Также можно получить изображения для всех объектов в кластерах при их наличии.
Задача Exporter#
С помощью этой задачи можно собирать данные о событиях и/или лицах и экспортировать их из LP в CSV-файл. В строке файла представлены запрошенные объекты и соответствующие биометрические образцы (если они были запрошены).
При сборе данных с помощью этой задачи используется память. Поэтому, вполне возможно, что "рабочий процесс" Task будет завершён OOM (Out-Of-Memory) killer при запросе большого количества данных.
Экспортировать данные о событиях или лицах можно с помощью запроса "/tasks/exporter". Необходимо указать, какой тип объекта требуется, установив параметр objects_type при создании запроса. Также можно сузить количество данных для запроса, задав фильтры для лиц и событий. См. запрос "exporter task" в справочном руководстве сервиса API.
В результате выполнения задачи возвращается ZIP-архив, содержащий CSV-файл.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
При выполнении задачи Exporter с большим количеством лиц базе данных Faces (например, 90 000 000 лиц), время выполнения запросов к сервису Faces может быть значительно увеличено. Для ускорения выполнения запросов можно задать для настройки PostgreSQL "parallel_setup_cost" значение
500. Однако следует учитывать, что изменение данной настройки может повлечь за собой другие последствия, поэтому следует внимательно отнестись к изменению настройки.Для такой задачи можно создать расписание.
Задача Cross-matching#
При выполнении задачи выполняется сравнение всех эталонов со всем кандидатами. Кандидаты и эталоны задаются на основе фильтров для лиц и событий.
Сравнение выполняется только для объектов, содержащих извлеченные биометрические шаблоны.
В поле limit можно указать максимальное количество кандидатов сравнения, выдаваемых для каждого совпадения.
Можно установить threshold, чтобы указать минимально допустимое значение схожести. Если схожесть двух БШ ниже указанного значения, результат сравнения будет проигнорирован и не будет выдаваться в ответе. Эталоны без совпадений с кандидатами также будут проигнорированы.
Сравнение выполняется в несколько этапов:
- На основе указанных фильтров подбираются объекты с БШ.
- Каждый объект-эталон сравнивается с каждым объектом-кандидатом.
- Результаты сравнения сортируются (лексикографически) и фильтруются (применяются
limitиthreshold).
Можно получить информацию о статусе задачи или результатах с помощью дополнительных запросов (см. "Общая информация о задачах").
В результате выполнения задачи возвращается массив. Каждый элемент массива содержит эталон и наиболее похожие кандидаты для него. Информация об ошибках, возникших при выполнении задачи, также выдается в ответе.
{
"result": [
{
"reference_id": "e99d42df-6859-4ab7-98d4-dafd18f47f30",
"candidates": [
{
"candidate_id": "93de0ea1-0d21-4b67-8f3f-d871c159b740",
"similarity": 0.548252
},
{
"candidate_id": "54860fc6-c726-4521-9c7f-3fa354983e02",
"similarity": 0.62344
}
]
},
{
"reference_id": "345af6e3-625b-4f09-a54c-3be4c834780d",
"candidates": [
{
"candidate_id": "6ade1494-1138-49ac-bfd3-29e9f5027240",
"similarity": 0.7123213
},
{
"candidate_id": "e0e3c474-9099-4fad-ac61-d892cd6688bf",
"similarity": 0.9543
}
]
}
],
"errors": [
{
"error_id": 10,
"task_id": 123,
"subtask_id": 5,
"error_code": 0,
"description": "Faces not found",
"detail": "One or more faces not found, including face with id '8f4f0070-c464-460b-bf78-fac225df72e9'",
"additional_info": "8f4f0070-c464-460b-bf78-fac225df72e9",
"error_time": "2018-08-11T09:11:41.674Z"
}
]
}
Для такой задачи можно создать расписание.
Задача Linker#
С помощью данной задачи можно прикреплять лица к спискам в соответствии с заданными фильтрами.
В запросе можно указать создание нового списка для привязки к нему или задать уже существующий список.
Для выполнения задачи можно задать фильтры для лиц или событий. Если для привязки к списку задано событие, новое лицо создается на основе этого события.
Если не указан фильтр create_time_lt, будет установлено текущее время.
В результате выполнения задачи выдаются идентификаторы лиц, привязанных к списку.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
Процесс выполнения задачи Linker для лиц:
- Проверяется наличие списка с указанным
list_idили создаётся новый список (если установлен параметрcreate_list, равный 1). - Определяются границы идентификатора лица. Затем формируется одна или несколько подзадач примерно по 1000 идентификаторов лиц в каждой – в зависимости от распространения идентификаторов лиц.
-
Для каждой подзадачи:
- Определяются идентификаторы лиц, указанные для текущей подзадачи в соответствии с фильтрами в подзадаче.
- Выполняется запрос в сервис Faces на привязку указанных лиц к указанному списку.
- Результат каждой подзадачи сохраняется в сервисе Image Store.
-
После завершения последней подзадачи, "рабочий процесс" собирает результаты всех подзадач, объединяет и помещает их в сервис Image Store (в виде результатов задачи).
Процесс выполнения задачи Linker для событий:
- Проверяется наличие списка с указанным
list_idили создаётся новый список (если установлен параметрcreate_list, равный 1). - Получение номера страниц с событиями. Затем формируется одна или несколько подзадач.
-
Для каждой подзадачи:
- С сервиса Events передается событие с его БШ.
- В сервисе Faces создается лицо, к нему прикрепляются атрибуты и биометрические образцы.
- Выполняется запрос в сервис Faces на привязку указанных лиц к указанному списку.
- Результат каждой подзадачи сохраняется в сервисе Image Store.
-
После завершения последней подзадачи, "рабочий процесс" собирает результаты всех подзадач, объединяет и помещает их в сервис Image Store (в виде результатов задачи).
Для такой задачи можно создать расписание.
Задача Garbage collection#
При обработке задачи могут быть удалены лица, события, общие события или биометрические шаблоны.
- когда БШ заданы в качестве
targetдля удаления, необходимо указать версию БШ для удаления. Все БШ указанной версии будут удалены. - если события заданы в качестве
targetдля удаления, необходимо указать один или несколько следующих параметров: - идентификатор учетной записи;
- верхнее исключенное пороговое значение времени создания события;
- верхнее исключенное пороговое значение появления события в видеопотоке;
- идентификатор обработчика, использованного для создания события.
- если лица заданы в качестве
targetдля удаления, необходимо указать один или несколько следующих параметров: - верхнее исключенное пороговое значение времени создания лица;
- нижнее включенное пороговое значение времени создания лица;
- пользовательские данные.
- идентификатор списка;
При необходимости можно удалить биометрические образцы, связанные с удаляемыми лицами или событиями. Для событий также можно удалить исходные изображения.
С помощью запроса "tasks" > "garbage collection task" сервиса API можно указать события (значение events), общего события (значение general_events) или лица (значение faces) в качестве значений для поля target, тогда как в сервисах Admin или Tasks можно задавать в качестве target лица, события, общие события и БШ (значение descriptors). В таком случае указанные объекты будут удалены для всех существующих аккаунтов.
Для такой задачи можно создать расписание.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
Задача Additional extraction#
Задача Additional extraction повторно извлекает биометрические шаблоны, извлеченные с помощью предыдущей модели нейронной сети, с использованием новой версии нейронной сети. Это позволяет сохранить используемые ранее биометрические шаблоны при обновлении модели нейронной сети. Если нет необходимости в использовании старых БШ, то можно не выполнять данную задачу и просто обновить модель нейронной сети в настройках Configurator.
В данном разделе описывается работа с задачей Additional extraction. См. подробную информацию о нейросетях, процессе обновления нейросети на новую модель и соответствующие примеры в разделе "Нейросети".
Повторное извлечение можно выполнить для объектов лиц и событий. Можно повторно извлечь БШ лиц, БШ тел (для событий) или базовые атрибуты, если они не были извлечены ранее.
Для повторного извлечения биометрических шаблонов с помощью новой нейросети необходимы биометрические образцы. БШ новой версии не будут извлечены для лиц и событий, у которых отсутствуют биометрические образцы.
Крайне рекомендуется не выполнять никаких запросов, изменяющих состояние баз данных в процессе обновления версии БШ. Это может привести к потере данных.
Создайте резервную копию баз данных LP и хранилища Image Store перед запуском задачи Additional extraction.
При обработке задачи извлекается БШ новой нейросети для каждого объекта (лица или события), чья версия биометрического шаблона совпадает с версией, указанной в настройках "DEFAULT_FACE_DESCRIPTOR_VERSION" (для лиц) или "DEFAULT_HUMAN_DESCRIPTOR_VERSION" (для тел). Биометрические шаблоны, чья версия не совпадает с версией, указанной в данных настройках, повторно не извлекаются. Их можно удалить с помощью задачи Garbage collection.
Запрос к сервису Admin:
Необходимо выполнить запрос к ресурсу /additional_extract, указав следующие параметры в теле запроса:
- content > extraction_target – цель извлечения: БШ лица, БШ тела или базовые атрибуты
- content > options > descriptor_version – новая версия нейронной сети (не применимо для базовых атрибутов)
- content > filters > object_type – тип объекта: лица или события
При необходимости можно дополнительно отфильтровать тип объекта по "account_id", "face_id__lt" и пр.
Для дополнительной информации см. запрос "create additional extract task" в спецификации OpenAPI сервиса Admin.
Для получения статуса задачи или результата её выполнения используются специальные запросы (см. "Общая информация о задачах").
Пользовательский интерфейс сервиса Admin:
Необходимо выполнить следующие действия:
-
Открыть пользовательский интерфейс сервиса Admin:
http://<admin_server_ip>:5010/tasks; -
Запустить задачу Additional extraction, нажав на соответствующую кнопку;
-
В появившемся окне задать тип объекта (лица или события), цель извлечения (БШ лица, БШ тела или базовые атрибуты), новую модель нейросети (неприменимо для базовых атрибутов) и нажать "Start", подтвердив запуск задачи.
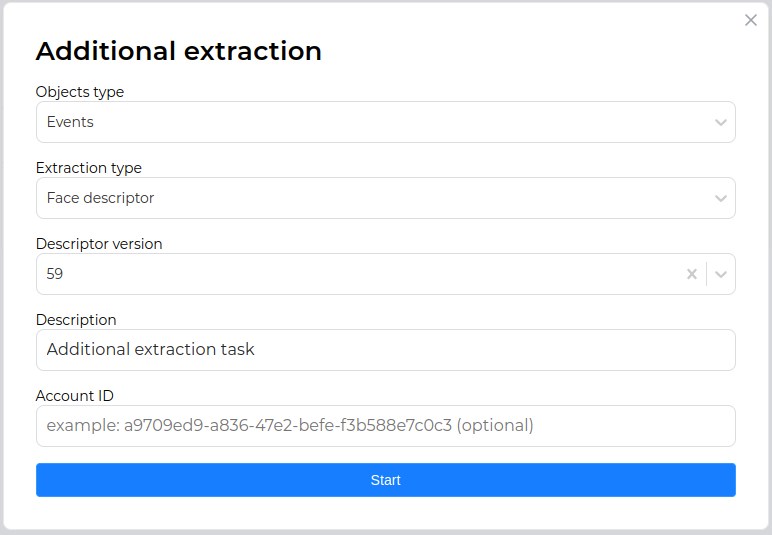
При необходимости можно дополнительно отфильтровать тип объекта по "account_id".
См. подробную информацию о пользовательском интерфейсе Admin в разделе "Пользовательский интерфейс сервиса Admin".
Для такой задачи можно создать расписание.
Задача ROC-curve calculating#
В результате выполнения этой задачи создается кривая рабочих характеристик приема с TPR (истинно положительной частотой) против FPR (ложно положительной частотой).
См. дополнительную информацию о построении ROC кривой в документе "TasksDevelopmentManual".
Задача расчета ROC
ROC (Receiver Operating Characteristic) – это измерение производительности для задач классификации при различных настройках пороговых значений. ROC-кривая строится в виде отношения TPR (True Positive Rate) к FPR (False Positive Rate). TPR – это количество пар истинно положительных совпадений, деленное на общее предполагаемое количество пар положительных совпадений, а FPR – количество пар ложных положительных совпадений, деленное на общее предполагаемое количество пар отрицательных совпадений. Каждая точка (FPR, TPR) ROC-кривой соответствует определенному порогу схожести. См. дополнительную информацию в Wikipedia.
При использовании ROC производительность модели определяется следующим образом:
- область под ROC-кривой (или AUC);
- частота ошибок типа I и типа II равна точке, то есть точке пересечения ROC-кривой и вторичной главной диагонали.
Производительность модели также определяется попаданием в топ-N вероятности, то есть вероятность попадания положительной пары сравнения в топ-N для любой группы результатов сравнения, отсортированной по схожести.
Для выполнения задачи ROC требуется предварительно созданная разметка. При желании можно указать threshold_hit_top (по умолчанию 0) для расчета попадания в топ-N вероятность, сравнить limit (по умолчанию 5), key_FPRs – список ключевых значений FPR для расчета ключевых точек ROC-кривой и фильтры с account_id. Также для создания задачи нужен account_id.
Для получения статуса задачи или результатов её выполнения используются специальные запросы (см. "Общая информация о задачах").
Разметка
Разметка предполагается в следующем формате:
[{'face_id': <face_id>, 'label': <label>}]
Метка (или идентификатор группы) может быть числом или любой строкой.
Пример:
[{'face_id': '94ae2c69-277a-4e46-817d-543f7d3446e2', 'label': 0},
{'face_id': 'cd6b52be-cdc1-40a8-938b-a97a1f77d196', 'label': 1},
{'face_id': 'cb9bda07-8e95-4d71-98ee-5905a36ec74a', 'label': 2},
{'face_id': '4e5e32bb-113d-4c22-ac7f-8f6b48736378', 'label': 3},
{'face_id': 'c43c0c0f-1368-41c0-b51c-f78a96672900', 'label': 2}]
Для такой задачи можно создать расписание.
Задача Estimator#
Задача Estimator позволяет выполнять пакетную обработку изображений с использованием указанных политик.
В результате выполнения задачи возвращается JSON с данными для каждого из обработанных изображений и информацией о произошедших ошибках.
В теле запроса можно указать handler_id уже существующего статического или динамического обработчика. Для handler_id динамического обработчика доступна возможность задания требуемых политик. Кроме того, в запросе можно создать статический обработчик с указанием политик.
Ресурс может принимать в обработку пять типов источников с изображениями:
- ZIP-архив
- S3-подобное хранилище
- Сетевой диск
- FTP-сервер
- Сетевая файловая система Samba
Для получения корректных результатов обработки изображений с помощью задачи Estimator все обрабатываемые изображения должны быть либо в исходном формате, либо в формате биометрических образцов. Тип передаваемых изображений для всех источников указывается в теле запроса в параметре "image_type".
Для такой задачи можно создать расписание. При создании расписания невозможно указать ZIP-архив в качестве источника изображений.
ZIP-архив как источник изображений для задачи Estimator
Размер архива задаётся с помощью параметра "ARCHIVE_MAX_SIZE" в конфигурационном файле "config.py" сервиса Tasks. По умолчанию размер равен 100 Гб. В качестве ссылки на архив можно использовать внешний URL-адрес или URL-адрес архива, сохраненного в Image Store. Во втором случае архив сначала следует сохранить в LP с помощью запроса POST к ресурсу "/objects".
При использовании внешнего URL-адреса, ZIP-архив сначала скачивается в хранилище контейнера Tasks Worker, где происходит распаковка и обработка изображений. После окончания работы задачи архив вместе с распакованными изображениями удаляются из хранилища.
Необходимо учитывать наличие свободного места для вышеописанных действий.
Передаваемый архив может быть защищён паролем. Пароль можно передать в запросе с помощью параметра "authorization" > "password".
S3-подобное хранилище как источник изображений для задачи Estimator
Для такого типа источника доступно задание следующих параметров:
- Параметр "bucket_name" — имя бакета/Access Point ARN/Outpost ARN (обязательное действие);
- Параметр "endpoint" — endpoint (только при указании имени бакета);
- Параметр "region" — bucket region (только при указании имени бакета);
- Параметр "prefix" — префикс ключа файла. Также может использоваться для загрузки изображений из определенной папки, например, "2022/January".
Для настройки авторизации предназначены следующие параметры:
- Public access key (обязательное действие);
- Secret access key (обязательное действие);
- Signature version ("s3v2"/"s3v4").
Также доступна возможность рекурсивного выкачивания изображений из вложенных папок бакета (параметр "recursive") и сохранения исходных изображений (параметр "save_origin").
Дополнительную информацию о работе с S3-подобными хранилищами см. в руководстве пользователя AWS.
Сетевой диск как источник изображений для задачи Estimator
Для такого типа источника доступно задание следующих параметров:
- Параметр "path" — абсолютный путь к директории с изображениями в контейнере (обязательное поле);
- Параметр "follow_links" — включение/выключение обработки символических ссылок (symlink);
- Параметр "prefix" — префикс ключа файла. Может использоваться для загрузки изображений из определенной директории;
- Параметр "postfix" — постфикс ключа файла. Может использоваться для загрузки изображений с определенным расширением.
См. пример использования префиксов и постфиксов в описании ресурса "/tasks/estimator".
При использовании такого типа источника и запуске сервисов Tasks и Tasks Worker через Docker-контейнеры необходимо смонтировать директорию с изображениями с сетевого диска в локальную директорию и синхронизировать её с указанной директорией в контейнере. Смонтировать директорию с сетевого диска можно любым удобным способом. После этого можно синхронизировать смонтированную директорию с директорией в контейнере с помощью следующей команды при запуске сервисов Tasks и Tasks Worker:
docker run \
...
-v /var/lib/luna/current/images:/srv/images
...
/var/lib/luna/current/images — путь к предварительно смонтированной директории с изображениями с сетевого диска.
/srv/images — путь к директории с изображениями в контейнере, куда они будут перенесены с сетевого диска. Этот путь должен быть указан в теле запроса задачи Estimator (параметр "path").
Как и в задаче Estimator с использованием S3-подобного хранилища в качестве источника изображений, доступна возможность рекурсивного получения изображений из вложенных директорий бакета и выбора типа передаваемых изображений.
FTP-сервер как источник изображений для задачи Estimator
Для такого типа источника в теле запроса доступно задание следующих параметров для соединения с FTP-сервером:
- Параметр "host" — IP-адрес или имя хоста FTP-сервера (обязательное поле);
- Параметр "port" — порт FTP-сервера;
- Параметр "max_sessions" — максимальное количество разрешенных сеансов на FTP-сервере;
- Параметры "user" и "password" — параметры авторизации (обязательные поля).
Как и в задачах Estimator с использованием S3-подобного хранилища или сетевого диска в качестве источников изображений, доступна возможность задания пути до директории с изображениями, рекурсивного получения изображений из вложенных директорий, выбора типа передаваемых изображений, а также указания префикса и постфикса.
См. пример использования префиксов и постфиксов в описании ресурса "/tasks/estimator".
Samba как источник изображений для задачи Estimator
Для такого типа источника параметры аналогичны параметрам FTP-сервера, за исключением параметра "max_sessions". Также если не указываются данные авторизации, подключение к Samba будет осуществляться как гостевое.
Обработка задачи#
Сервис Tasks включает в себя "рабочие процессы" Tasks. Сервис Tasks получает запросы, создает задачи в БД и отправляет подзадачи "рабочим процессам" Tasks. "Рабочие процессы" сервиса Tasks реализованы в виде отдельного контейнера Tasks Worker. "Рабочие процессы" Tasks получают подзадачи и выполняют все необходимые запросы к другим сервисам для решения подзадач.
Ниже представлен общий подход к работе с задачами.
- Сервис API получает запрос на создание новой задачи;
- Сервис Tasks создает новую задачу и отправляет подзадачи "рабочим процессам";
- "Рабочие процессы" Tasks обрабатывают подзадачи и создают отчеты;
- Если несколько "рабочих процессов" обработали подзадачи и создали несколько отчетов, "рабочий процесс", выполнивший последнюю подзадачу, собирает все отчеты и создает единый отчет;
- После завершения выполнения задачи последний "рабочий процесс" обновляет свой статус в базе данных Tasks;
- Пользователь может отправлять запросы на получение информации о задачах и подзадачах и количестве активных задач. Пользователь может отменять или удалять задачи;
- Пользователь может получать информацию об ошибках, возникших при выполнении задач;
- После завершения выполнения задачи пользователь может отправить запрос на получение результатов задачи.
См. раздел "Диаграммы задач" для получения подробной информации об обработке задач.
Запуск задач по расписанию#
В LUNA PLATFORM доступна возможность задать расписание выполнения задач Garbage collection, Clusterization, Exporter, Linker, Estimator, Additional extract, Cross-matching и Roc-curve calculating. С помощью расписания можно гибко управлять временем начала выполнения задач. Например, можно настроить регулярное расписание для очистки событий старше одного месяца каждую пятницу в ночное время.
Для использования фильтра относительно текущего времени ("now-time"), текущее время будет отсчитываться не от создания расписания, а от создания задачи расписанием в соответствии с cron-выражением. См. подробную информацию в разделе "Фильтры now-time".
Расписание создается с помощью запроса "create tasks schedule" к сервису API, в котором указывается содержимое создаваемой задачи и временной интервал её запуска. Для указания временного интервала используются Cron-выражения.
Cron-выражения используются для определения расписания выполнения задач. Они состоят из пяти полей, разделенных пробелами. Каждое поле определяет определенный временной интервал, в котором задача должна быть выполнена. Номер недели начинается с воскресенья.
Тем задачам, которые можно выполнить только через сервис Admin (например, задача удаления некоторых объектов через GC), можно назначить расписание только в сервисе Admin.
В ответ на запрос выдается уникальный идентификатор "schedule_id", по которому можно получить информацию о статусе задачи, время выполнения следующей задачи и пр. (запросы "get tasks schedule и "get tasks schedules). Идентификатор и вся дополнительная информация сохраняются в таблицу "schedule" БД Tasks.
При необходимости можно создать отложенное расписание, а затем активировать его с помощью параметра "action" = "start" запроса "patch tasks schedule". Аналогично можно остановить работу задачи по расписанию с помощью "action" = "stop". Для удаления расписания можно воспользоваться запросом "delete tasks schedule".
Права на работу с расписаниями задаются в токене разрешением "task". Это означает, что если у пользователя есть разрешение на работу с задачами, то он также сможет воспользоваться расписанием.
Возможность создания расписания также доступна для задач Lambda.
Примеры Cron-выражений#
В данном разделе описаны различные примеры Cron-выражений.
- Запускать задачу каждый день в 3 часа ночи:
0 3 * * *
- Запускать задачу каждую пятницу в 18:30:
30 18 * * 5
- Запускать задачу каждый первый день месяца в полдень:
0 12 1 * *
- Запускать задачу каждые 15 минут:
*/15 * * * *
- Запускать задачу каждое утро в 8:00, кроме выходных (суббота и воскресенье):
0 8 * * 1-5
- Запускать задачу в 9:00 утра в первый и 15-й день каждого месяца, но только если это понедельник:
0 9 1,15 * 1
Отправка уведомлений об изменении статуса задач и подзадач#
При необходимости можно отправлять уведомления об изменении статуса задач и подзадач с помощью механизма callback'ов. Callback'и позволяют отправлять данные в стороннюю систему по указанному URL или в Telegram. Для настройки уведомлений необходимо настроить политику "notification_policy" в параметрах запроса соответствущей задачи.
Также можно настроить отправку уведомлений для задач и подзадач в настройках расписания.
При необходимости можно получить информацию о текущем состоянии политики уведомления или изменить какие-то данные политики с помощью запросов "get task notification policy" и "replace task notification policy".
Дополнительная защита паролей и токенов#
Пароли и токены, передаваемые в задаче Estimator и в политике "notification_policy", могут быть дополнительно зашифрованы. Для этого необходимо при старте контейнера сервиса Tasks передать пользовательские значения переменным окружения FERNET_PASSPHRASE и SALT.
FERNET_PASSPHRASE — это пароль или ключ, используемый для шифрования данных с помощью алгоритма Fernet.
SALT — это случайная строка, добавляемая к паролю перед его хешированием.
Fernet — это симметричный алгоритм шифрования, который обеспечивает аутентификацию и целостность данных, а также конфиденциальность. При использовании этого алгоритма один и тот же ключ используется для шифрования и дешифрования данных.
Salt добавляется для усложнения процесса взлома пароля методом подбора. Каждый раз, когда пароль хешируется, используется уникальная строка, что делает одинаковые пароли хешированными по-разному. Это повышает безопасность системы, особенно в случае, если у пользователей есть одинаковые пароли.
Пример команды запуска контейнера с передачей переменных окружения:
docker run \
--env=CONFIGURATOR_HOST=127.0.0.1 \
--env=FERNET_PASSPHRASE=security_passphrase \
--env=SALT=salt_for_passwords_and_tokens \
...
Важно! Когда контейнер запускается с указанием вышеописанных переменных окружений, то старые пароли и токены перестают работать. Необходимо выполнить дополнительные действия по миграции (см. раздел ниже).
Добавление шифрования при обновлении#
Для того, чтобы добавить дополнительную защиту для уже существующих паролей и токенов, необходимо в команде миграции БД Tasks указать переменные окружения (см. выше). После чего необходимо запустить новый контейнер Tasks с указанием переменных окружения для возможности использования шифрования при создании новых объектов.
Сервис Admin#
Сервис Admin используется для выполнения общих административных процедур:
- Управление учетными записями пользователей;
- Получение информации об объектах, принадлежащих разным учетным записям;
- Создание задач Garbage collection;
- Создание задач Additional extraction;
- Получение отчетов и ошибок по обработанным задачам;
- Отмена и удаление существующих задач.
Сервис Admin имеет доступ ко всем данным, привязанным к разным учетным записям.
В сервисе Admin можно создать аккаунт трех типов — "user", "advanced_user" и "admin". Первые два типа создаются с помощью запроса на создание аккаунта к сервису API, однако третий тип можно создать только с помощью сервиса Admin.
С помощью типа аккаунта "admin" можно авторизироваться в пользовательском интерфейсе (см. ниже) и выполнять вышеописанные задачи. Аккаунт с типом "admin" можно создать как в пользовательском интерфейсе, так и с помощью запроса к ресурсу /accounts сервиса Admin. Для создания аккаунта последним способом требуется указать логин и пароль.
Если аккаунт создается впервые, то необходимо использовать логин и пароль по умолчанию.
Пример CURL-запроса к ресурсу /accounts сервиса Admin:
curl --location --request POST 'http://127.0.0.1:5010/4/accounts' \
--header 'Authorization: Basic cm9vdEB2aXNpb25sYWJzLmFpOnJvb3Q=' \
--header 'Content-Type: application/json' \
--data '{
"login": "mylogin@gmail.com",
"password": "password",
"account_type": "admin",
"description": "description"
}'
Все запросы к сервису Admin описаны спецификации OpenAPI сервиса Admin.
Пользовательский интерфейс сервиса Admin#
Пользовательский интерфейс сервиса Admin предназначен для упрощения работы с административными задачами.
Интерфейс можно открыть в браузере, указав адрес и порт сервиса Admin: <Admin_server_address>:<Admin_server_port>.
Порт сервиса Admin по умолчанию — 5010.
Логин и пароль по умолчанию для доступа к интерфейсу — root@visionlabs.ai/root. Также можно использовать логин и пароль по умолчанию в формате Base64 при запросе к ресурсу /accounts (см. ниже) — cm9vdEB2aXNpb25sYWJzLmFpOnJvb3Q=.
Можно изменить пароль по умолчанию для сервиса Admin с помощью запроса "Change authorization".
На странице доступно три вкладки:
- Accounts. Вкладка предназначена для предоставления информации о всех созданных аккаунтах и для создания новых аккаунтов.
- Tasks. Вкладка предназначена для работы с задачами Garbage Collection и Additional extraction.
- Info. Вкладка содержит информацию о пользовательском интерфейсе и лицензии LUNA PLATFORM.
Вкладка Accounts#
На данной вкладке отображаются все существующие аккаунты.
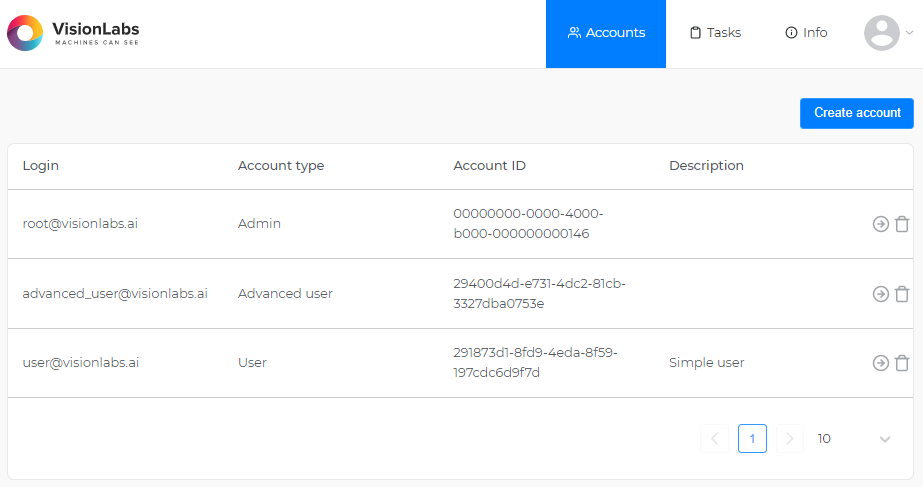
Можно управлять существующими аккаунтами с помощью следующих кнопок:
![]() – просмотр информации об аккаунте.
– просмотр информации об аккаунте.
![]() – удаление аккаунта.
– удаление аккаунта.
При нажатии кнопки просмотра информации открывается страница, содержащая общую информацию об аккаунте, списках, созданных с помощью данного аккаунта, и лицах.
При нажатии кнопки "Create account" открывается окно создания аккаунта, содержащее стандартные настройки создания аккаунта — логин, пароль, тип аккаунта, описание и желаемый "account_id".
См. подробную информацию об аккаунтах и их типах в разделе "Аккаунт".
Вкладка Tasks#
На данной вкладке отображаются выполняемые/выполненные задачи Garbage collection и Additional extraction.
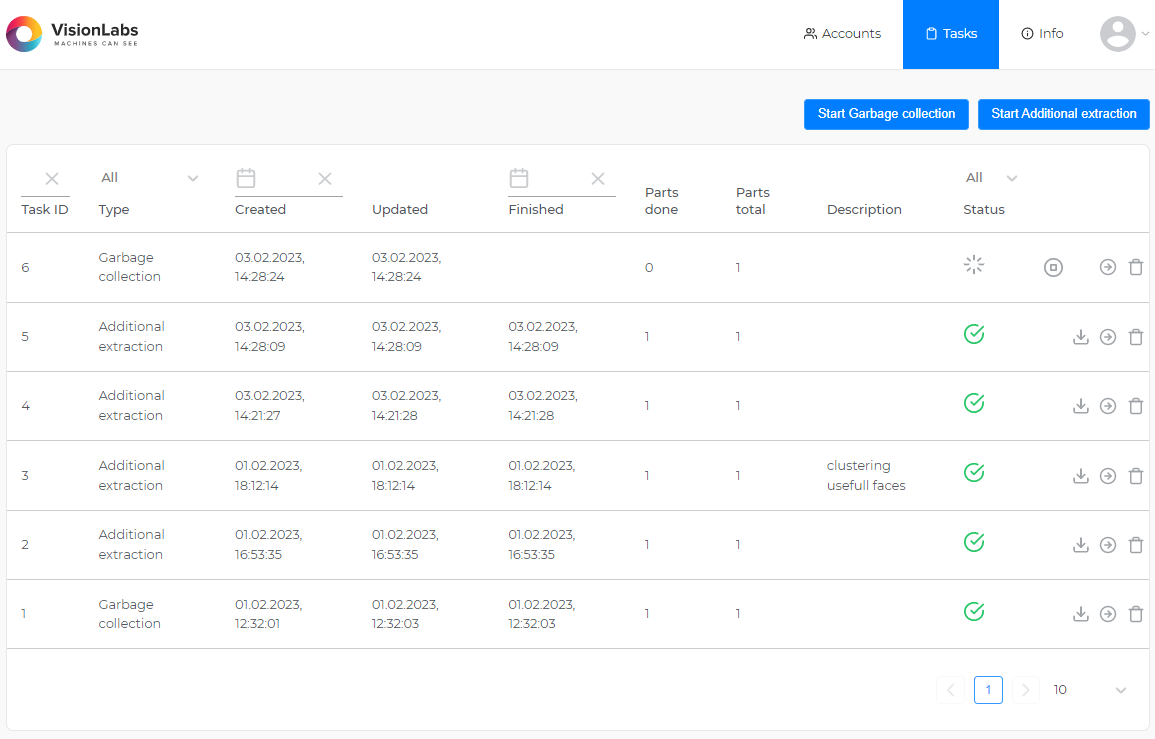
.
Задачи отображаются в таблице, столбцы которой можно сортировать, а также фильтровать по дате выполнения задач.
При нажатии кнопок "Start Garbage collection" и "Start Additional extraction" открываются окна создания соответствующих задач.
Окно "Garbage collection" содержит следующие настройки, аналогичные параметрам тела запроса "garbage collecting task" к сервису Tasks:
- Description — параметр "description"
- Target — параметр "content > target"
- Account ID — параметр "content > filters > account_id"
- Remove sample — параметр "content > remove_samples"
- Remove image origins — параметр "content > remove_image_origins"
- Delete data before — параметр "content > create_time__lt"
См. подробную информацию в разделе "Задача Garbage collection".
Окно "Additional extraction" содержит следующие настройки, аналогичные параметрам тела запроса "additional extract task" к сервису Tasks:
- Objects type — параметр "content > filters > object_type"
- Extraction type — параметр "content > extraction_target"
- Descriptor version — параметр "content > options > descriptor_version"
- Description — параметр "description"
- Account ID — параметр "content > filters > account_id"
См. подробную информацию в разделе "Задача Additional extraction".
После создания задачи, начинается её выполнение. Процесс выполнения задачи отображается икнонкой ![]() . Задача считается выполненной когда значение "Parts done" совпадает со значением "Parts total" и иконка меняется на
. Задача считается выполненной когда значение "Parts done" совпадает со значением "Parts total" и иконка меняется на ![]() . При необходимости можно остановить выполнение задачи с помощью иконки
. При необходимости можно остановить выполнение задачи с помощью иконки ![]() .
.
Для каждой задачи доступны следующие кнопки:
![]() – скачивание результата выполнения задачи в виде файла формата JSON.
– скачивание результата выполнения задачи в виде файла формата JSON.
![]() – переход на страницу подробного описания задачи и ошибок, полученных при её выполнении.
– переход на страницу подробного описания задачи и ошибок, полученных при её выполнении.
![]() – удаление задачи.
– удаление задачи.
Задачи выполняются сервисом Tasks после получения запроса от сервиса Admin.
Вкладка Schedules#
Данная вкладка предназначена для работы с расписанием задач.
Во вкладке отображаются все созданные расписания задач и вся соответствующая информация (статус, идентификатор, Cron-строка и т.д.).
При нажатии на кнопку "Create schedule" открывается окно создания расписания.

В окне можно задать настройки расписания для задачи Garbage collection. Параметры в данном окне соответствуют параметрам запроса "create tasks schedule".
После заполнения параметров и нажатия кнопки "Create schedule" расписание появится во вкладке Schedules.
Можно управлять отложенным запуском с помощью следующих кнопок:
![]() – запуск расписания.
– запуск расписания.
![]() – остановка расписания.
– остановка расписания.
С помощью кнопки ![]() можно редактировать расписание. С помощью кнопки
можно редактировать расписание. С помощью кнопки ![]() можно удалить расписание.
можно удалить расписание.
Вкладка Info#
На данной вкладке отображается полная информация о лицензии и возможности, которые можно выполнить с помощью пользовательского интерфейса Admin.
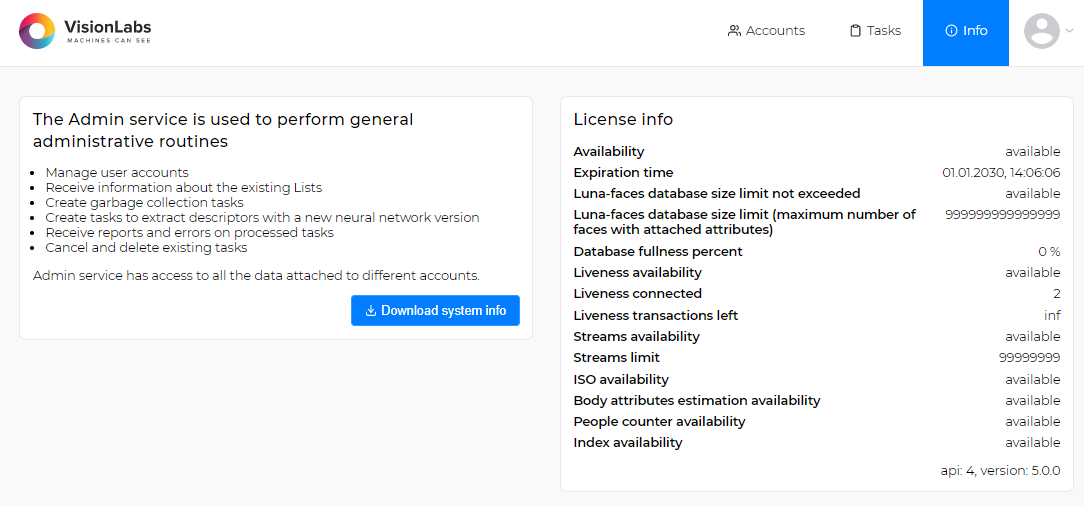
.
См. подробное описание лицензии в разделе "Информация о лицензии".
Нажав на кнопку "Download system info" можно также получить следующую техническую информацию о LP:
- версия LUNA PLATFORM,
- версии сервисов LUNA PLATFORM,
- количество биометрических шаблонов,
- значения конфигурационных файлов,
- информация о лицензии,
- статистика выполненных запросов и оценок (см. "Подсчет статистики выполненных запросов и оценок").
Эта информация необходима для технической поддержки. При отправке вопроса необходимо приложить к письму полученный файл JSON.
Получить вышеперечисленную системную информацию также можно с помощью запроса "get system info" к сервису Admin.
Сервис Configurator#
С помощью сервиса Configurator упрощается настройка сервисов LP.
Сервис сохраняет все необходимые конфигурации для всех сервисов LP в одном месте. Можно редактировать конфигурации с использованием пользовательского интерфейса или специальных файлов с ограничениями.
Также можно сохранить в Configurator конфигурации для любого стороннего программного обеспечения.
Общий процесс работы выглядит следующим образом:
- Пользователь редактирует конфигурации в пользовательском интерфейсе;
- Сервис Configurator сохраняет все измененные конфигурации и другие данные в базе данных;
- Сервисы LP запрашивают сервис Configurator во время запуска и получают все необходимые конфигурации. Все сервисы должны быть настроены на использование сервиса Configurator.
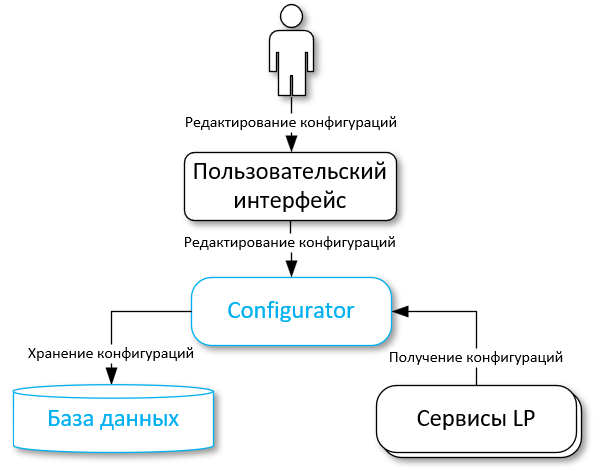
При установке сервиса Configurator также можно использовать свой файл с ограничениями со всеми обязательными полями для создания ограничений и заполнения базы данных Configurator. Более подробную информацию об этом процессе можно найти в "руководстве разработчика".
Настройки, используемые несколькими сервисами, обновляются для каждого из них. Например, при изменении параметра "LUNA_FACES_ADDRESS" для сервиса Handlers в пользовательском интерфейсе Configurator, этот параметр также будет обновлен для сервисов API, Admin и Python Matcher.
Пользовательский интерфейс сервиса Configurator#
Пользовательский интерфейс сервиса Configurator доступен по следующему адресу: <Configurator_server_address> :5070.
URL может отличаться. В этом примере интерфейс сервиса Configurator открывается на сервере сервиса Configurator.
LP содержит бета-версию пользовательского интерфейса сервиса Configurator. Пользовательский интерфейс тестировался в браузерах Chrome и Yandex. Рекомендуемое разрешение экрана для работы с пользовательским интерфейсом – 1920 x 1080.
В пользовательском интерфейсе Configurator доступны следующие вкладки:
- Settings. Все данные в сервисе Configurator хранятся во вкладке Settings. На этой вкладке отображаются все имеющиеся настройки. Также можно управлять ими и фильтровать;
- Limitations. Эта вкладка используется для создания новых ограничений для настроек. Ограничениями являются шаблоны для файлов JSON, содержащие тип имеющихся данных и другие правила для определения параметров;
- Groups. С помощью этой вкладки можно сгруппировать все необходимые настройки. При выборе группы на вкладке Settings, будут отображаться только настройки, соответствующие группе. Можно получить настройки в соответствии с фильтрами и/или тегами для одного определенного сервиса.
- About. В этой вкладке содержится информация об интерфейсе сервиса Configurator.
Настройки#
Каждая настройка сервиса Configurator содержит следующие поля:
- Name – название настройки.
- Description – описание настройки;
- ID and Times – уникальный идентификатор настройки;
- Create time – время создания настройки;
- Last update time – время последнего обновления настройки;
- Value – тело настройки;
- Schema – шаблон проверки тела схемы;
- Tag – теги для настройки, используемые для фильтрации настроек для сервисов.
В поле "Tag" отсутствуют настройки по умолчанию. Необходимо нажать кнопку Duplicate и создать новую настройку на основе имеющейся.
Доступны следующие варианты настроек:
-
Создание новой настройки – нажать кнопку Create new, ввести необходимые значения и нажать Create. Также необходимо выбрать уже имеющееся существующее ограничение для настройки. Сервис Configurator попытается проверить значение параметра, если будет стоять флажок напротив Check on save и для параметра будет выбрано ограничение;
-
Дублирование имеющейся настройки – нажать кнопку Duplicate справа от настройки, изменить требуемые значения и нажать Create. Сервис Configurator попытается проверить значение настройки, если в левой нижней части экрана будет установлен флажок напротив Check on save и будет такая возможность;
-
Удаление имеющейся настройки – нажать кнопку Delete справа от настройки.
-
Обновление имеющейся настройки – нужно изменить имя, описание, теги, значение и нажать кнопку Save справа от настройки.
-
Фильтрование имеющихся настроек по имени, описанию, тегам, именам сервисов, группам – нужно указать фильтры в левой части экрана и нажать Enter или нажать кнопку Search;
Show limitations – флаг используется для включения отображения ограничений для каждой настройки.
JSON editors – с помощью флага можно переключать режим отображения поля значений. При отсутствии флага отображается наименование параметра и поле его значения. При наличии флага поле Value отображается в виде JSON.
В разделе Filters в левой части окна могут отображаться все необходимые настройки в соответствии с указанными значениями. Нужное наименование можно ввести вручную или выбрать из списка:
- Setting. При использовании данного фильтра будет отображаться определенная настройка с указанным именем.
- Description. При использовании данного фильтра будут отображаться все настройки с указанным описанием или частью описания.
- Tags. При использовании данного фильтра будут отображаться все настройки с указанным тегом.
- Service filter. При использовании данного фильтра будут отображаться все настройки, относящиеся к выбранному сервису.
- Group. При использовании данного фильтра будут отображаться все настройки, принадлежащие указанной группе. Например, можно выбрать, чтобы отображались все сервисы, принадлежащие LP.
Использование тегированных настроек#
С помощью тегированных настроек можно запустить несколько одинаковых сервисов, которые будут использовать различные настройки из Configurator.
Для этого необходимо выполнить следующие действия:
-
Дублировать или создать новую настройку, указав ей тег. Например, можно дублировать настройку "LUNA_EVENTS_DB" и присвоить ей тег "EVENTS_DB_TAG".
-
Передать следующие аргументы в команду "run.py" соответствующего контейнера:
-
--luna-config— флаг, содержащий адрес сервиса Configurator --<configuration_name>— флаг, содержащий настройку и тег
См. дополнительную информацию по аргументам в разделе "Аргументы сервисов" руководства по установке.
Например, для настройки "LUNA_EVENTS_DB" с тегом "EVENTS_DB_TAG" команда запуска контейнера будет выглядеть следующим образом:
docker run \
...
dockerhub.visionlabs.ru/luna/luna-events:v.4.16.0
python3 /srv/luna_events/run.py --luna-config http://127.0.0.1:5070/1 --LUNA_EVENTS_DB EVENTS_DB_TAG
Ограничения#
Ограничения используются в качестве схемы проверки параметров сервиса.
Настройки и ограничения имеют одинаковые наименования. При создании ограничения создается новая настройка.
Ограничения установлены по умолчанию для каждого сервиса LP. Их нельзя изменить.
Каждое ограничение содержит следующие поля:
- Name – наименование ограничения.
- Description – описание ограничения.
- Service list – список сервисов, в которых могут использоваться настройки этого ограничения.
- Schema – это объект со схемой JSON для проверки настроек.
- Default value – это значение по умолчанию, установленное при создании ограничения.
Для управления ограничениями можно выполнить следующие действия:
- Создание нового ограничения – нажать кнопку Create new, ввести необходимые значения и нажать Create. Также будет создана настройка со значением по умолчанию;
- Дублирование существующего ограничения – нажать кнопку Duplicate справа от ограничения, изменить требуемые значения и нажать Create. Также будет создана настройка со значением по умолчанию;
- Обновление значения ограничения – изменить name/description/service list/validation schema/default values и нажать кнопку Save справа от ограничения;
- Фильтрование существующего ограничения по именам, описаниям и группам;
- Удаление существующего ограничения – нажать кнопку Delete справа от ограничения.
Группы#
У группы есть наименование и описание.
Можно:
- Создать новую группу – нажать кнопку Create new, ввести имя группы и, при необходимости, описание и нажать Create;
- Отфильтровать существующие группы по именам групп и/или именам ограничений – задать фильтры с левой стороны и нажать RETURN или нажать кнопку Search;
- Обновить описание группы – обновить существующее описание и нажать кнопку Save справа от группы;
- Обновить список, привязанный к ограничениям – чтобы отменить привязку ограничения, нужно нажать кнопку "-" справа от имени ограничения, чтобы привязать ограничение, нужно ввести его имя в поле внизу списка ограничений и нажать кнопку "+". Чтобы принять изменения, нужно нажать кнопку Save;
- Удалить группу – нажать кнопку Delete справа от группы.
Дамп-файл с настройками LP#
Дамп-файл с настройками LP содержит все настройки всех сервисов LP.
Получение дамп-файла#
Можно извлечь существующие настройки сервиса из Configurator, создав дамп-файл. Это может понадобиться для сохранения текущих настроек сервиса.
Чтобы получить дамп-файл необходимо воспользоваться следующими командами:
- wget:
wget -O settings_dump.json 127.0.0.1:5070/1/dump; - curl:
curl 127.0.0.1:5070/1/dump > settings_dump.json; - редактор текста.
Будут получены текущие значения, имеющиеся в сервисе Configurator.
Применение дамп-файла#
Чтобы применить сохраненные настройки, нужно использовать скрипт db_create.py с аргументом командной строки--dump-file (за которым следует имя созданного дамп-файла): base_scripts/db_create.py --dump-file settings_dump.json.
Применить дамп-файл можно только к пустой базе данных с созданными таблицами. Если требуется обновление настроек, перед его применением следует удалить всю группу "limitations" из дамп-файла.
"limitations":[
...
],
Для применения дамп-файла нужно выполнить следующие действия:
-
Войти в контейнер сервиса Configurator;
-
Запустить скрипт
python3 base_scripts/db_create.py --dump-file settings_dump.json
Ограничения из существующих файлов ограничений заменяются ограничениями из дамп-файла, если наименования ограничений совпадают.
Файл с ограничениями#
Получение файла с ограничениями#
Файл с ограничениями содержит ограничения указанного сервиса. Он не содержит имеющиеся настройки и их значения.
Чтобы загрузить файл с ограничениями для одного или нескольких сервисов, необходимо выполнить следующие команды:
-
Войти в контейнер сервиса Configurator;
-
Создать выходной каталог base_scripts/results:
mkdir base_scripts/results; -
Запустить скрипт base_scripts/get_limitation.py:
python3 base_scripts/get_limitation.py --service luna-image-store luna-handlers --output base_scripts/results/my_limitations.json.
Обратите внимание на параметры скрипта base_scripts/get_limitation.py:
--serviceдля указания одного или нескольких имен сервисов (обязательно);--outputдля указания каталога или файла для сохранения выходных данных. Значение по умолчанию: current_dir/{timestamp}_limitation.json (необязательно).
Авторизация#
В сервисе Configurator доступна возможность использования авторизации типа BasicAuth для запросов, логически требущих авторизации.
Использование авторизации позволяет обеспечить дополнительную степень безопасности для шифрования и защиты от несанкционированного доступа.
Для включения авторизации нужно задать следующие настройки из новой секции "LUNA_CONFIGURATOR_AUTHORIZATION" сервиса Configurator:
- "USE_AUTHORIZATION" - включение/выключение авторизации
- "LUNA_CONFIGURATOR_USER" - логин, который будет использоваться другими сервисами для авторизации
- "LUNA_CONFIGURATOR_PASS" - пароль, который будет использоваться другими сервисами для авторизации
Задать настройки можно двумя способами:
- передача настроек через переменную окружения
VL_SETTINGSпри старте сервиса. Например:
env "VL_SETTINGS.LUNA_CONFIGURATOR.USE_AUTHORIZATION=1"
env "VL_SETTINGS.LUNA_CONFIGURATOR.LUNA_CONFIGURATOR_USER=luna"
env "VL_SETTINGS.LUNA_CONFIGURATOR.LUNA_CONFIGURATOR_PASS=root"
- передача настроек в конфигурационный файл сервиса Configurator. Конфигурационный файл сервиса Configurator расположен по следующему пути в поставке
example-docker/luna_configurator/configs/luna_configurator_postgres.conf
Для того, чтобы остальные сервисы LUNA PLATFORM могли выполнять запросы к сервису Configurator нужно передать им логин и пароль. Это можно сделать с помощью следующих способов:
- передача настроек "LUNA_CONFIGURATOR_USER" и "LUNA_CONFIGURATOR" через переменную окружения
VL_SETTINGSпри старте сервиса (см. пример выше) - передача настроек "LUNA_CONFIGURATOR_USER" и "LUNA_CONFIGURATOR в конфигурационный файл сервиса при его использовании
Сервис Licenses#
Общая информация#
Сервис Licenses содержит информацию о доступных лицензируемых возможностях и их ограничениях.
Получить информацию о лицензии можно тремя способами:
- с помощью запроса "get license" к сервису Licenses
- с помощью запроса "get system info" к сервису Admin
- с помощью пользовательского интерфейса сервиса Admin
Также можно использовать запрос "get platform features", в ответе на который можно получить информацию о состоянии лицензии, включенных функциях лицензии ("face_quality", "body_attributes" и "liveness") и состоянии опциональных сервисов Image Store, Events, Tasks и Sender из настройки "ADDITIONAL_SERVICES_USAGE" сервиса Configurator.
Если отключить какую-то лицензируемую функцию, и попытаться использовать запрос, требующий этой функции, то будет возвращена ошибка 33002 с описанием "License problem Failed to get value of License feature {value}".
Информация о лицензии#
Лицензия LP содержит следующие параметры:
- Дату окончания лицензии.
- Максимальное количество лиц с прикрепленными биометрическими шаблонами или базовыми атрибутами.
- Доступность функционала OneShotLiveness.
- Текущее количество транзакций OneShotLiveness.
- Доступность функционала Deepfake.
- Доступность функционала для проверки изображений на соответствие стандарту ISO/IEC 19794-5:2011.
- Доступность функционала оценки параметров тел.
- Доступность функционала оценки количества людей на изображении.
- Возможность использования сервиса Lambda.
- Возможность использования сервиса Indexed Matcher в модуле LUNA Index Module.
- Максимально допустимое одновременное количество потоков, которые могут быть взяты единовременно в обработку из FaceStream.
- Максимально допустимое одновременное количество потоков, которые могут быть взяты единовременно в обработку из сервиса Video Manager.
При заказе лицензии нужно сообщить в техническую поддержку о необходимости использования какого-либо из вышеперечисленных параметров.
Параметры "Возможность использования сервиса Indexed Matcher в модуле LUNA Index Module" и "Максимально допустимое одновременное количество потоков, которые могут быть взяты единовременно в обработку из FaceStream" описаны в документации LUNA Index Module и FaceStream соответственно.
Для некоторых параметров доступны уведомления при приближении к лимиту. Уведомления работают в виде отправки сообщений в логи соответствующего сервиса. Например, при приближении к допустимому количество созданных лиц с биометрическими шаблонами, в логах сервиса Faces будет выводиться следующее сообщение: "License limit exceeded: 8 % of the available license limit is used. Please contact VisionLabs for license upgrade or delete redundant faces". Уведомления работают за счет постоянного мониторинга, реализованного с помощью базы данных Influx. Данные мониторинга сохраняются в соответствующие поля базы данных Influx.
См. подробную информацию в разделе "Мониторинг".
Дата окончания лицензии#
После истечения срока действия лицензии невозможно продолжать использование LUNA PLATFORM.
По умолчанию уведомление об окончании срока действия лицензии отправляется за две недели до истечения срока действия.
Когда срок действия лицензии истекает, сервис API выдает сообщение "License has expired. Please contact VisionLabs for license extension."
Сервис Licenses пишет данные о сроке истечения лицензии в логи и базу мониторинга Influx в поле "license_period_rest".
Максимальное количество лиц#
Сервис Faces проверяет количество оставшихся лиц на основе информации о максимально возможном количестве лиц из сервиса Licenses. Учитываются только лица со связанными биометрическими шаблонами или лица со связанными базовыми атрибутами.
Процент созданных лиц записывается в логах сервиса Faces и отображается в пользовательском интерфейсе Admin.
Сервис Faces пишет данные о созданных лицах в логи и базу мониторинга Influx в поле "license_faces_limit_rate".
Система начинает присылать уведомления, когда остается 15% от общего количества доступных лиц. При превышении максимального количества доступных лиц, в журналах появится сообщение "License limit exceeded: 8 % of the available license limit is used. Please contact VisionLabs for license upgrade or delete redundant faces". К лицам нельзя прикреплять атрибуты, если количество лиц превышает 110%.
Последствия отсутствия параметра
При отключении данного параметра, будет невозможно выполнить следующие запросы:
- "create face"
- "generate events" с указанием обработчика с "policies" > "storage_policy" > "face_policy" > "store_face"
OneShotLiveness#
Для оценки Liveness с помощью эстиматора OneShotLiveness доступна безлимитная лицензия или лицензия с ограниченным количеством транзакций.
Каждое использование Liveness в запросах уменьшает счётчик транзакций. После исчерпания лимита транзакций будет невозможно использовать оценку Liveness в запросах. На запросы не использующие Liveness или с отключённой оценкой Liveness исчерпание лимита не влияет, они продолжают работать в обычном режиме.
Сервис Licenses содержит информацию о количестве оставшихся транзакций Liveness. Оно отображается в ответе ресурса "/license".
Сервис Remote SDK пишет данные о количестве доступных транзакций Liveness в логи и базу мониторинга Influx в поле "liveness_balance".
Система начинает присылать уведомления при достижении 2000 оставшихся транзакций Liveness (данный порог задан в системе).
См. раздел "Описание OneShotLiveness" для более подробной информации о работе Liveness.
Последствия отсутствия параметра
При отключении данного параметра, будет невозможно выполнить оценку Liveness (параметр "estimate_liveness") в следующих запросах:
- "sdk"
- "detect faces"
- "generate events" с указанием обработчика с "policies" > "detect_policy" > "estimate_liveness"
- "perform verification" с указанием обработчика с "policies" > "detect_policy" > "estimate_liveness"
- "estimator task" с указанием обработчика с "policies" > "detect_policy" > "estimate_liveness"
- "predict liveness"
Оценка параметров тел#
Данный параметр позволяет выполнять оценку параметров тел. В лицензии может быть задано два значения — 0 или 1. Для данного параметра не предназначен мониторинг.
Последствия отсутствия параметра
При отключении данного параметра, будет невозможно выполнить оценку параметров тел (параметры "estimate_upper_body", "estimate_lower_body", "estimate_body_basic_attributes", "estimate_accessories") в следующих запросах:
- "sdk"
- "generate events" с указанием обработчика с "policies" > "detect_policy" > "body_attributes"
Оценка количества людей#
Данный параметр позволяет выполнять оценку количества людей. В лицензии может быть задано два значения — 0 или 1. Для данного параметра не предназначен мониторинг.
Последствия отсутствия параметра
При отключении данного параметра, будет невозможно выполнить оценку количества людей (параметр "estimate_people_count") в следующих запросах:
- "sdk"
- "generate events" с указанием обработчика с "policies" > "detect_policy" > "estimate_people_count"
Проверка по стандарту ISO/IEC 19794-5:2011#
Данный параметр позволяет выполнять различные проверки изображений на соответствие стандарту ISO/IEC 19794-5:2011. В лицензии может быть задано два значения — 0 или 1. Для данного параметра не предназначен мониторинг.
Последствия отсутствия параметра
При отключении данного параметра, будет невозможно выполнить следующие запросы:
- "iso"
- "detect faces" с параметром "estimate_face_quality"
- "generate events" с указанием обработчика с "policies" > "detect_policy" > "face_quality"
- "estimator task" с указанием обработчика с "policies" > "detect_policy" > "face_quality"
- "perform verification" с указанием обработчика с "policies" > "detect_policy" > "face_quality"
Сервисы видеоаналитики#
Сервисы видеоаналитики предназначены для обработки видеофайлов или видеопотоков с целью выполнения различных аналитических задач. Эти задачи могут включать в себя подсчет людей, отслеживание людей на кадре, детектирование драк и многое другое.
Далее в документации для обозначения обрабатываемой сущности (видеофайла или видеопотока) будет использоваться понятие поток.
Работа сервисов видеоаналитики основана на взаимодействии трех ключевых компонентов: аналитик, агентов и сервиса Video Manager.
Примечание. Для возможности создания потоков требуется лицензируемая функция, определяющая максимально допустимое одновременное количество потоков, обрабатываемых сервисом Video Agent. Сервис Video Manager проверяет наличие лицензии каждый раз при создании потока, а также проверяет отчеты (если они есть) для определения количества обрабатываемых потоков сервисом Video Agent. См. подробную информацию о лицензируемых функциях в разделе "Сервис Licenses".
Аналитика
Аналитика представляет собой набор алгоритмов, которые выполняют определенные задачи по обработке потоков. Для каждой аналитики предусмотрен набор параметров, который может быть настроен пользователем. Video Manager хранит информацию о доступных аналитиках и передает ее агентам, которые реализуют соответствующие алгоритмы.
Агент
Агент — это компонент, который реализует алгоритмы видеоаналитики. Он принимает потоки, выполняет заданную аналитику и отправляет результаты через механизм Callback'ов.
В качестве агента можно использовать сервис Video Agent, либо написать собственного агента. См. пример кода в руководстве разработчика сервиса Video Manager.
Сервис Video Agent предоставляет следующие аналитики:
Video Manager
Video Manager выступает в роли координатора между пользователями и агентами. Он содержит информацию о доступных аналитиках и распределяет видеопотоки на обработку среди агентов. Video Manager также отвечает за управление потоками, следит за их статусом и координирует автоматический перезапуск потоков в случае возникновения ошибок.
См. подробную информацию о взаимодействии сервиса Video Manager и агента в разделе "Взаимодействие Video Manager и агента".
Базовый принцип работы выглядит следующим образом:

- Пользователь выполняет запрос на создание потока с помощью запроса "create stream".
- Сервис Video Manager направляет поток агенту, способному обработать все аналитики, переданные в запросе.
- Агент обрабатывает поток и отправляет статус обработки и возможные ошибки сервису Video Manager.
- Агент отправляет результаты обработки в соответствии с выбранным типом Callback'ов (см. раздел "Отправка и сохранение событий").
Также можно получить результаты обработки, выполнив запрос
stream events ws handshake, позволяющий установить веб-сокет соединение для получения результатов обработки конкретного потока в реальном времени с помощью указания "stream_id".
Пользователь также может пересоздавать поток, получать статус обработки потока, останавливать и запускать поток и др. См. подробную информацию в группе запросов streams спецификации OpenAPI.
См. подробную информацию о том как пользователь использует сервисы видеоаналитики в разделе "Взаимодействие пользователя и Video Manager".
См. раздел "Быстрое начало по созданию потока" ниже для изучения базовых шагов по созданию потока.
См. подробную информацию в разделе "Взаимодействие Video Manager и агента".
Отправка и сохранение событий#
Агент может отправлять результаты обработки через механизм Callback'ов с типами:
- "http", предварительно настроив сервер для приема сообщений
- "luna-ws-notification", предварительно установив веб-сокет соединение
- "luna-event"
Типы "http" и "luna-ws-notification" являются стандартными. См. раздел "Отправка событий в сторонний сервис".
Тип "luna-event" предназначен для сохранения событий в базу данных Events с использованием механизма общих событий. Получить такие события можно с помощью запросов "get general events" и "get general event", указав в качестве фильтра полученный идентификатор "stream_id".
Аналитики#
С точки зрения сервиса Video Manager, аналитика представляет собой объект, содержащий имя, неизвестный набор параметров и, при необходимости, описание и документацию. Аналитику создает либо агент, либо администратор, отправляя запрос "create analytic" в сервис Video Manager.
В сервисе Video Agent доступно две аналитики -
people_countиhuman_tracking. Аналитики автоматически регистрируется при запуске сервиса Video Agent.
Video Manager распределяет потоки по агентам, в том числе опираясь на знание того, какой агент готов сделать ту или иную аналитику. Когда агент или администратор создает аналитику, он может указать набор параметров, которые будут использоваться при запуске аналитики. Однако при создании запроса на обработку потока пользователь может указать и другие параметры, которые будут использоваться в рамках этой аналитики (используя параметр "analytics" > "parameters" запроса "create stream").
Подробная информация о доступных параметрах и их описаниях различна для каждой аналитики. Она доступна в документации соответствующей аналитики и может быть получена в ответ на запрос "get analytics".
Взаимодействие пользователя и Video Manager#
Для выполнения аналитики потока пользователь должен создать поток, указав желаемую аналитику.
Для создания потока необходимо сделать запрос "create stream". Для пересоздания потока необходимо сделать запрос "put stream", в этом случае будут использованы новые данные потока, а версия потока будет увеличена на 1.
После появления нового потока он переходит в статус "pending".
Когда поток обрабатывается одним из доступных агентов (см. раздел "Распределение потоков"), он будет иметь статус "in_progress".
Пока происходит обработка потока, агент отправляет обратную связь сервису Video Manager, который создает логи, которые может получить пользователь, выполнив запрос "get streams logs".
Обработку потока можно остановить:
-
по запросу пользователя (запрос "patch stream" с параметром "action" = "stop"). В таком случае статус потока будет "stop".
-
по запросу пользователя (запрос "remove stream"). В таком случае поток будет удален.
-
когда поток закончится. В таком случае статус потока будет "done".
-
при возникновении фатальной ошибки. В таком случае статус потока будет "failure".
Во всех случаях, за исключением ручного удаления логов с помощью запроса "delete stream logs", логи потоков будут доступны после выполнения запроса "get streams logs".
Во всех случаях, за исключением удаления потока с помощью запроса "remove stream", данные потока будут доступны после выполнения запроса "get stream".
Взаимодействие Video Manager и агента#
Взаимодействие сервиса Video Manager и агента описано ниже:
-
Агент или администратор должен зарегистрировать в сервисе Video Manager аналитику с которой агент умеет работать, выполнив запрос к ресурсу
/1/analyticсервиса Video Manager. -
При старте агент должен выполнить запрос к ресурсу
/1/agentсервиса Video Manager на регистрацию самого себя. В данном запросе указываются следующие параметры:- имя агента (обязательно)
- максимальное количество потоков, которое может обрабатывать агент (обязательно)
- набор аналитик, с которыми может работать агент (обязательно)
- описание агента
В ответе на запрос агент получит уникальный идентификатор "agent_id".
-
Агент периодически должен выполнять запросы к ресурсу
/1/agent/{agent_id}/streamsсервиса Video Manager для получения/остановки потока на обработку.Как только агент получил поток на обработку, сервис Video Manager запускает счетчик потоков, обрабатываемых данным агентом.
Обратите внимание, что если агент не сделает такой запрос вовремя, статус агента будет помечен как "not_ready" и агент будет исключен из списка агентов, которые могут обрабатывать потоки (подробности см. в разделе "Управление статусом агента в случае отсутствия запроса агента").
-
Во время обработки, агент должен отправлять обратную связь о статусе обработки потока к ресурсу
/1/agent/{agent_id}/streams/feedback.Отчет содержит идентификатор потока, его статус, ошибку, версию потока и время генерации отчета. После отправки отчета пользователь может получить логи обработки с помощью запроса "get streams logs".
Обратите внимание, что пользовательский агент должен вышеописанные действия. См. пример кода в разделе "Agent interaction" в руководстве разработчика сервиса Video Manager.
Сервис Video Agent автоматически выполняет вышеописанные действия.
Потоки#
Потоки создает пользователь с помощью запроса "create stream".
Пользователь может задать имя потока, его описание, добавить информацию о городе или улице, настроить автоматический перезапуск потока, задать параметры группировки потока, аналитки, также нижеперечисленные общие данные обработки потока:
- "type" - тип источника: видеофайл или видеопоток
- "reference" - адрес источника
- "rotation" - угол поворота кадра камеры
-
"downloadable" - определяет необходимость предварительного скачивания видеофайла перед его обработкой
Предварительная загрузка необходима для:
- Успешного декодирования видеофайлов. Для некоторых файлов могут возникнуть ошибки декодирования, если файлы не будут предварительно сохранены.
- Длительных процессов обработки. Если обработка видео занимает значительное время, хранение предотвращает проблемы, связанные с разрывом соединения.
Обратите внимание, что иногда политики безопасности запрещают сохранение видеофайлов. В таких случаях предварительное скачивание может быть не применимо.
-
"timestamp_source" - определяет, откуда будут браться временные метки для видеоанализа.
Доступны следующие значения:
- "pts" - Использует временные метки видео, если они существуют, для точного отображения времени воспроизведения. Метки не всегда могут быть корректными (см. ниже).
- "server" - Применяет серверное время для видеопотока, что гарантирует единообразие и синхронизацию с другими событиями.
- "frame_rate" - Применяет частоту кадров для видеофайлов, что помогает приблизительно определить временные метки.
- "auto" (по умолчанию) - Автоматически выбирает источник времени, сначала проверяя временные метки ("pts"), а затем переключаясь на серверное время ("server") или частоту кадров ("frame_rate"), если метки некорректны.
Корректные метки для видеофайла означают, что временные метки (PTS) должны быть близки к нулю, то есть время от начала видео до метки должно быть относительно небольшим (абсолютное значение не должно превышать 10^5 секунд).
Корректные метки для видеопотока означают, что время видеопотока отличается от времени сервера менее чем на 1 день.
-
"pts" > "start_time" - смещение для временных меток видео (PTS)
Указание смещения позволяет синхронизировать начало обработки видео с конкретным моментом времени. Это может быть полезно, например, если видео обрабатывается частями и необходимо, чтобы временные метки новых частей продолжали последовательность с предыдущих. Таким образом, при нарезке большого видео на маленькие фрагменты, временные метки будут отображаться так, как если бы обрабатывалось одно целое видео.
Формат потоков, поддерживаемый сервисом Video Agent#
Сервис Video Agent может обрабатывать потоки в различных форматах. Если формат потока не соответствует поддерживаемым, возникает ошибка. При этом ведется запись логов и поток считается неудачным. В общем, сервис Video Agent поддерживает обработку всех потоков, которые могут быть обработаны с использованием ffmpeg, но существует известное ограничение на формат пикселей. Сервис Video Agent поддерживает следующие форматы пикселей: BGR, BGR_32F, NV12, P10, P12, RGB, RGB_32F, RGB_32F_PLANAR, RGB_PLANAR, YCBCR, YUV420, YUV420_10bit, YUV422, YUV444, YUV444_10bit.
Если поток имеет формат, который не поддерживается, его можно перекодировать, например, с помощью ffmpeg:
ffmpeg -rtsp_transport tcp -i <входной_поток> -rtsp_transport tcp -pix_fmt yuv420p -c:v copy -f rtsp <выходной_поток>
Важно! Описание выше распространяется только на сервис Video Agent. Если у пользователя собственный агент, то пользователь самостоятельно настраивает формат обработки потоков.
Статусы потока#
Поток может иметь следующие статусы:
- "pending" — поток взят в работу, но пока не найдено ни одного агента. Такой статус может быть сразу после создания, пересоздания потока и во время автоматического перезапуска
- "in_progress" — поток обрабатывается агентом
- "done" — поток полностью обработан
- "restart" — сервер перезапустил обработку потока с помощью автоматического перезапуска
- "failure" — от агента был получен отчет об ошибке обработки потока
- "cancel" — обработка потока была отменена, т.к. поток был удален из сервиса Video Manager
- "stop" — поток был остановлен с помощью запроса "patch stream"
Жизненный цикл потока#
Жизненный цикл потока представлен ниже:
- Поток создается с помощью запроса "create stream". Статус изменяется на "pending"
- Агент принимает поток для обработки. Статус изменяется на "in_progress".
- Опционально. Выполняется остановка/продолжение обработки потока:
- Выполняется запрос "patch stream" с параметром "action" = "stop". Статус изменяется на "stop"
- Выполняется запрос "patch stream" с параметром "action" = "resume". Статус изменяется на "pending" до того момента, как очередной агент не возьмет поток в обработку. При этом статус изменится на "in_progress"
- Окончание обработки:
- Окончание потока. Агент останавливает обработку и отправляет обратную связь сервису Video Manager. Статус изменяется на "done".
- Поток удаляется с помощью запроса "remove stream".
- Обработка заканчивается из-за ошибки, которую отправляет агент в обратной связи. Статус потока меняется на "failure".
Автоматический перезапуск потоков#
Возможность автоматического перезапуска потоков актуальна только для потоков со статусом "failure". Параметры автоматического перезапуска (возможность перезапуска, максимальное количество попыток перезапуска, задержка между попытками) задаются пользователем для каждого потока в разделе "autorestart" запроса "create stream". Параметры и статус автоматического перезапуска можно получить с помощью запроса "get stream".
Ниже перечислены статусы автоматического перезапуска:
- "disabled" — автоматический перезапуск отключен пользователем (отключен параметр "restart")
- "enabled" — автоматический перезапуск включен, но в данный момент не активен поскольку поток не находится в статуса "failure"
- "in_progress" — автоматический перезапуск в процессе
- "failed" — превышено допустимое количество попыток автоматического перезапуска и ни одна попытка не увенчалась успехом
Распределение потоков#
Сервис Video Manager распределяет потоки, предоставленные пользователями агентам, следующим образом:
-
выбирает все потоки, которые требуют обработки (обработке подлежат только потоки со статусом "pending"). См. раздел "Статусы потока" для более подробной информации.
-
выбирает все доступные агенты, количество потоков обработки которых в текущем режиме не достигает максимального количества потоков, доступных для одновременной обработки агентом. См. раздел "Взаимодействие Video Manager и агента" для более подробной информации.
-
в порядке очередности создания потоков выбирает агента для каждого потока, удовлетворяющего следующим условиям:
- агент может обрабатывать аналитику, указанную для потока
- есть свободный слот для потока (агент предоставляет параметр
max_stream_count- максимальное количество потоков, доступных ему для одновременной обработки, поэтому количество одновременных потоков для агента не может превышать это число)
-
вносит необходимые записи в базу данных для ответа на запрос агента в соответствии с предыдущей логикой
-
агент получает 2 типа потоков через запрос "get agent streams" — потоки, которые необходимо обработать, и потоки, обработка которых должна быть остановлена. Поток, однажды упомянутый в ответе на запрос, как поток, обработка которого должна быть начата, больше не будет упоминаться в ответах на этот запрос до тех пор, пока его обработку не потребуется остановить. То же самое относится и к потокам, обработку которых необходимо остановить — они больше не будут упоминаться в ответах на этот запрос до тех пор, пока их обработку не потребуется начать снова.
Описанная процедура будет выполняться как периодическая фоновая задача главного экземпляра. Период выполнения можно настроить с помощью параметра luna_video_manager_streams_agent_search_interval. Рекомендуется проконсультироваться со специалистами VisionLabs перед изменением данного параметра.
Процесс перезапуска потоков#
Ниже описан процесс обработки потоков с включенным автоматическим перезапуском. Описанные действия будут выполняться как периодическая фоновая задача главного экземпляра сервиса Video Manager, период выполнения можно настроить с помощью параметра luna_video_manager_streams_autorestarter_interval. Рекомендуется проконсультироваться со специалистами VisionLabs перед изменением данного параметра.
Когда происходит попытка автоматической перезагрузки потока данных, происходят следующие изменения:
- статус потока изменяется сначала на "restart", а затем на "pending";
- счетчик попыток автоматической перезагрузки "current_attempt" увеличивается на 1;
- запись времени последней попытки "last_attempt_time" обновляется, чтобы отразить актуальное время.
Для того чтобы произошла перезагрузка, должны соблюдаться следующие условия:
- статус потока должен находиться в состоянии "failure";
- должен быть включен автоматический перезапуск потока (параметр "restart");
- значение текущей попытки автоматической перезагрузки "current_attempt" должно быть равно "null" или меньше, чем максимальное число попыток "attempt_count";
- время последней попытки автоматической перезагрузки "last_attempt_time" должно быть равно "null" или разница между текущим временем и временем последней попытки должна быть больше или равна задержке "delay".
Если соблюдаются условия ниже, то произойдет сбой автоматического перезапуска потока (прекращение попыток перезапуска):
- статус потока находится в состоянии "failure";
- статус автоматического перезапуска потока находится в состоянии "in_progress";
- значение текущей попытки автоматической перезагрузки "current_attempt" равно значению максимального числа попыток "attempt_count".
Если соблюдаются условия ниже, то произойдет завершение работы автоматического перезапуска потока:
- статус потока не равен статусу "failure";
- статус автоматической перезагрузки потока находится в состоянии "in_progress";
- время последней попытки автоматической перезагрузки "last_attempt_time" равно "null" или разница между текущим временем и временем последней попытки больше или равна задержке "delay".
Группировка потоков#
Потоки можно группировать. Группировка призвана объединять потоки с множеством камер в логические группы. Например, можно группировать потоки по территориальному признаку.
Поток может привязан к нескольким группам.
Группа создается с помощью запроса "create group". Для создания группы нужно указать обязательный параметр "group_name". При необходимости можно указать описание группы.
Поток может быть привязан к группе с помощью параметров "group_name" или "group_id" во время создания потока (запрос "create stream").
Если поток был привязан к группе, то при запросе "get stream" или "get streams" группа будет отражена в поле "groups".
Работа с несколькими экземплярами#
Каждый экземпляр сервиса Video Manager может обслуживать ограниченное количество пользовательских запросов, а каждый агент может анализировать ограниченное количество потоков, поэтому эти сервисы можно масштабировать таким образом, чтобы каждый сервис Video Manager имел доступ к одной и той же базе данных и каждый агент имеет доступ к одному из экземпляров сервиса Video Manager.
Все запущенные экземпляры сервиса Video Manager выбирают главный экземпляр для корректного выполнения ключевых процессов, таких как:
- распределение потоков между агентами
- автоматический перезапуск потоков
- обработка потоков в случае не появления обратной связи
- управление статусом агента случае отсутствия запроса агента
Эти процессы должны выполняться только одним экземпляром, чтобы избежать состояния гонки, когда несколько экземпляров пытаются одновременно выполнять одни и те же задачи, что может привести к некорректной работе системы.
Выбор главного экземпляра#
Для выбора главного экземпляра каждый экземпляр сервиса пытается получить блокировку базы данных, обновляя поле в таблице single_process_lock. Если экземпляру удается получить блокировку, он объявляется главным экземпляром и сохраняет это состояние, регулярно отправляя в базу данных сигнал "heartbeat". Этот сигнал позволяет другим экземплярам знать, что главный экземпляр активен и выполняет свои задачи. Если сигнал "heartbeat" от главного экземпляра перестает поступать, это означает, что главный экземпляр больше не активен, и любой другой экземпляр может попытаться стать новым главным экземпляром, получив блокировку базы данных.
Таким образом, выбор главного экземпляра обеспечивает координацию и предотвращает конфликтные ситуации, гарантируя, что только один экземпляр выполняет критические задачи в любой момент времени.
Обработка потоков в случае не появления обратной связи#
Процесс обработки видеопотоков подразумевает получение обратной связи для каждого потока, находящегося в состоянии "in_progress". Сервис Video Manager периодически проверяет время последнего получения обратной связи по каждому потоку. Если обратная связь не была получена в установленное время, статус потока изменится на "restart", что означает попытку заново начать обработку потока. Затем статус потока сразу изменяется на "pending", чтобы поставить его в очередь на обработку.
Проверка условий для обновления статуса потоков выполняется как периодическое фоновое задание главным экземпляром. Период выполнения можно настроить с помощью параметра luna_video_manager_stream_status_obsoleting_interval. Потоки будут считаться устаревшими, если время последнего получения обратной связи превышает установленный период, который настраивается с помощью параметра luna_video_manager_stream_status_obsoleting_period.
Рекомендуется проконсультироваться со специалистами VisionLabs перед изменением данных параметров.
Управление статусом агента в случае отсутствия запроса агента#
Взаимодействие с агентами подразумевает периодические запросы к сервису Video Manager (см. раздел "Взаимодействие Video Manager и агента"). Сервис Video Manager периодически проверяет время последнего запроса агентов на обработку потоков, и если это время было слишком давно, статус агента изменяется на "not_ready", что означает исключение агента из очереди распределения потоков.
Если такой агент позже сделает запрос на обработку потоков, его статус будет обновлен на "ready", и агент будет добавлен в список агентов, которые могут обрабатывать потоки.
Проверка условий для обработки потоков в случае отсутствия запроса агента выполняется как периодическое фоновое задание главным экземпляром. Период выполнения можно настроить с помощью параметра luna_video_manager_agent_status_obsoleting_interval. Агенты будут считаться не готовыми, если последний запрос от агента не был получен вовремя, что можно настроить с помощью параметра luna_video_manager_agent_status_obsoleting_period.
Рекомендуется проконсультироваться со специалистами VisionLabs перед изменением данных параметров.
Настройка получения результатов аналитики#
Результат выполнения аналитики можно получить только с помощью механизма Callback'ов через веб-хуки или веб-сокеты. Соответственно, для получения результатов аналитики должно быть установлено соответветствующее соединение.
Если используются веб-хуки, то должен быть развернут сервер, принимающий уведомления. Если используются веб-сокеты, то сервис Sender должен быть включен в настройке "ADDITIONAL_SERVICE_USAGE" и должно быть установлено соединение с сервисом Sender (см. запрос "ws handshake for general events").
Также можно получать результаты эстимации (не события) в режиме реального времени с помощью запроса "stream events ws handshake". Так, например, если выполняется аналитика количества людей, то можно получать координаты людей в тот момент, когда они появляются на кадре.
Быстрое начало по созданию потока#
В данном примере будут описаны базовые действия для создания потока, его обработки и просмотра результатов обработки. В качестве агента будет использоваться сервис Video Agent.
1) Подготовьте тело запроса "create stream".
Секция "analytics" > "parameters" отличается для каждого типа аналитики. Узнать параметры конкретной аналитики можно с помощью соответствующих спецификаций в комплекте поставки по пути docs/ReferenceManuals или на сайте с онлайн-документацией.
Онлайн-документация:
Также можно получить документацию аналитики с помощью запроса "get analytic documentation", указав идентификатор аналитики, который можно получить с помощью запроса "get analytics". Запрос "get analytic documentation" подразумевает обращение к ресурсу
/6/analytics/{analytic_id}/docs. Рекомендуется открывать данный ресурс в браузере или указывать заголовок "Accept" = "text/html" для корректного отображения HTML-документации.
Содержимое параметров аналитики необходимо добавить в тело запроса "create stream".
Например, можно создать следующее тело запроса для аналитики people_count:
{
"name": "name_example",
"description": "description_example",
"data": {
"type": "videofile",
"reference": "https://example.com/humantracking.mp4",
"rotation": 0
},
"location": {
"city": "Moscow",
"area": "Central",
"district": "Basmanny",
"street": "Podsosensky lane",
"house_number": "23 bldg.3",
"geo_position": {
"longitude": 36.616,
"latitude": 55.752
}
},
"autorestart": {
"restart": 0,
"attempt_count": 10,
"delay": 60
},
"analytics": [
{
"analytic_name": "people_count",
"parameters": {
"parameters": {
"probe_count": 2,
"image_retain_policy": {
"mimetype": "PNG"
}
},
"callbacks": [
{
"type": "luna-event",
}
],
"targets": [
"coordinates",
"overview"
]
}
}
]
}
Сохраните полученный идентификатор "stream_id".
2) Выполните запрос "get general events" или "get general event" с приминением фильтра по "stream_id".
Сервис Lambda#
Сервис Lambda предназначен для работы с пользовательскими модулями, имитирующими функционал отдельного сервиса. Сервис позволяет написать и использовать собственный обработчик или написать внешний сервис, который будет тесно взаимодействовать с LUNA PLATFORM и сразу иметь несколько функций, типичных для сервисов LP (таких как логирование, автоматическая перезагрузка конфигураций и т.д.).
Сервис Lambda создает образ Docker, а затем запускает его в кластере Kubernetes. Без Kubernetes невозможно управлять пользовательским модулем. Полноценная работа с сервисом Lambda возможна только при разворачивании сервисов LUNA PLATFORM в Kubernetes. Для использования необходимо самостоятельно развернуть сервисы LUNA PLATFORM в Kubernetes или обратиться за консультацией к специалистам VisionLabs. При необходимости можно использовать Minikube для локальной разработки и тестирования, обеспечивая таким образом Kubernetes-подобную среду без необходимости управления полноценным продакшн Kubernetes-кластером.
Не следует путать данный функционал с механизмом плагинов. Плагины предназначены для реализации узкого целенаправленного функционала, в то время как сервис Lambda позволяет реализовывать функционал полноценных сервисов.
Настоятельно рекомендуется узнать как можно больше об объектах и механизмах LUNA PLATFORM (особенно об обработчиках), прежде чем приступать к работе с данным сервисом.
Пользовательский модуль, запущенный в кластере Kubernetes, называется lambda. Информация о созданной lambda хранится в базе данных Lambda.
Количество создаваемых lambda не ограничено. Для каждой lambda доступна возможность добавить свою спецификацию OpenAPI.
Для работы с сервисом Lambda нужна отдельная лицензируемая функция. Если функция недоступна, то при запросе на создание lambda будет возвращаться соответствующая ошибка.
Примечание. Описание, приведенное ниже, предназначено для общего знакомства с функционалом сервиса Lambda. Cм. руководство разработчика сервиса Lambda для более подробной информации. В руководстве разработчика доступен раздел "Quick start guide", позволяющий начать работу с сервисом.
Перед началом работы#
Перед началом работы с сервисом Lambda, необходимо ознакомиться со всеми требованиями и правильно задать настройки сервиса.
Требования к коду и архиву#
Модуль пишется на языке Python и должен быть передан в сервис Lambda в ZIP-архиве.
Код и архив должны соответствовать определенным требованиям, основные из которых перечислены ниже:
- должен использоваться Python версии 3.11 или выше;
- для разработки необходима библиотека "luna-lambda-tools", доступная в VisionLabs PyPi;
- архив не должен быть запаролен.
Также файлы в архиве должны иметь определенную структуру. См. подробную информацию в разделе "Requirements" руководства разработчика сервиса Lambda.
Требования к окружению#
Для работы с сервисом Lambda необходимы следующие требования к окружению:
- наличие запущенных сервисов Licenses и Configurator*;
- наличие бакета S3 для хранения архивов;
- наличие Docker registry для хранения образов;
- наличие кластера Kubernetes.
* во время своей работы, lambda будет дополнительно взаимодействовать с некоторыми сервисами LUNA PLATFORM. Перечень сервисов зависит от типа lambda (см. "Типы lambda").
При необходимости можно настроить TTL для хранения архивов в S3. См. раздел "Миграция для добавления TTL к объектам в S3".
Должен быть обеспечен доступ на запись/чтение в бакет хранилища S3 и настроены определенные права доступа в кластере Kubernetes. Необходимо переместить базовые образы Lambda на свой Docker registry. Команды для переноса образов приведены в документации по установке LUNA PLATFORM.
При старте сервиса Lambda выполняется проверка Docker registry и базовых образов.
См. подробную информацию в разделе "Requirements" руководства разработчика сервиса Lambda.
Настройки сервиса Lambda#
В настройках сервиса Lambda необходимо указать следующие данные:
-
местоположение кластера Kubernetes (см. настройку "CLUSTER_LOCATION"):
-
"internal" — сервис Lambda работает в кластере Kubernetes и не требует других дополнительных настроек;
- "remote" — сервис Lambda работает с удаленным кластером Kubernetes и правильно определенными настройками "CLUSTER_CREDENTIALS" (хост, токен и сертификат);
- "local"- сервис Lambda работает там же, где запущен кластер Kubernetes.
В классическом варианте работы с сервисом Lambda предполагается использование параметра "internal".
-
настройки бакета S3 (см. настройку "S3");
-
адрес реестра (registry) для хранения образа Docker (см. настройку "LAMBDA_REGISTRY");
-
адреса небезопасных реестров (registry), к которым может понадобиться доступ во время создания lambda (см. настройку "LAMBDA_INSECURE_REGISTRIES").
См. подробную информацию в разделе "Configuration requirements" руководства разработчика сервиса Lambda.
Настройка сущностей lambda#
Для запущенных сущностей lambda доступен определенный набор настроек. Их можно задать в Configurator, отфильтровав настройки по имени "luna-lambda-unit".
Настройки для сервиса Lambda и настройки для сущностей lambda отличаются.
Настройки содержат адреса сервисов, тайм-ауты подключения, настройки логирования и др., позволяющие сущностям lambda эффективно взаимодействовать с сервисами LUNA PLATFORM. См. все доступные настройки в разделе "Настройки lambda".
Настройки распространяются на все lambda одновременно.
Типы lambda#
Lambda может быть трех типов:
- Тип Handlers-lambda, предназначенный для замены функционала классического обработчика.
- Тип Standalone-lambda, предназначенный для реализации самостоятельного функционала для выполнения тесной интеграции с LUNA PLATFORM.
- Тип Tasks-lambda, предназначенный для реализации дополнительных пользовательских длинных типов задач.
У каждого типа есть определенные требования к сервисам LUNA PLATFORM, фактические настройки которых будут автоматически использоваться для обработки запросов. Перед началом работы пользователь должен определиться какая lambda ему необходима.
Handlers-lambda#
Примеры возможного функционала:
- выполнение верификации с возможностью сохранения какого-либо события;
- сравнение двух изображений без выполнения остального функционала классического обработчика;
- добавление собственной логики фильтрации в функционал сравнения;
- обход определенных ограничений LUNA PLATFORM (например, указать количество максимальное кандидатов больше 100);
- встраивание нейронной сети SDK в обход LUNA PLATFORM.
Во время своей работы, Handlers-lambda будет взаимодействовать со следующими сервисами LUNA PLATFORM:
- Configurator — для получения настроек,
- Faces — для работы лицами и списками,
- Remote SDK — для выполнение детекций, эстимаций и извлечений,
- Events* — для работы с событиями,
- Python Matcher / Python Matcher Proxy** — для классического/перекрестного сравнения лиц или тел
- Image Store* — для хранения БО и исходных изображений лиц или тел
Сервис Lambda не будет проверять подключение к отключенным сервисам и выдаст ошибку, если пользователь попытается сделать запрос к отключенному сервису.
Для запуска сервиса Lambda требуется только наличие сервисов Configurator и Licenses.
* сервис может быть отключен в настройке "ADDITIONAL_SERVICES_USAGE"
** сервис по умолчанию отключен, для включения см. настройку "ADDITIONAL_SERVICES_USAGE"
Lambda-обработчик может использоваться в двух случаях:
- как пользовательский обработчик, который имеет свою собственную схему ответа, которая может отличаться от ответа классических обработчиков и не может быть должным образом использована в других сервисах LUNA PLATFORM
-
как пользовательский обработчик, который имитирует ответ классического обработчика. К такому случаю предъявляются некоторые требования:
- ответ должен соответствовать схеме ответа запроса на генерацию события;
- обработчик должен правильно обрабатывать входящие данные, чтобы другие сервисы могли его использовать, в противном случае нет гарантии совместимости с другими сервисами. То есть если такой обработчик подразумевает распознавание лиц — модуль должен возвращать информацию о распознавании лиц в ответ, если обработчик подразумевает обнаружение тел — модуль должен возвращать обнаружение тел в ответ и т.д.
Например, если Lambda-обработчик удовлетворяет вышеуказанным условиям, то его можно использовать в задаче Estimator в качестве классического обработчика.
См. подробную информацию и примеры кода для Handlers-lambda, в разделе "Handlers lambda development" руководства разработчика сервиса Lambda.
Standalone-lambda#
Примеры возможного функционала:
- фильтрация входящих изображений по формату для последующей отправки в сервис Remote SDK;
- создание сервиса для отправки уведомлений по аналогии с сервисом Sender;
- создание сервиса для записи видеопотока и сохранения в виде видеофайла в сервис Image Store для последующей обработки приложением FaceStream.
Во время своей работы, Standalone-lambda будет взаимодействовать как минимум с сервисом Configurator, который позволяет lambda получать свои настройки (например, настройки логирования).
Для запуска сервиса Lambda требуется только наличие сервисов Configurator и Licenses.
См. подробную информацию и пример кода для Standalone-lambda, в разделе "Standalone lambda development" руководства разработчика сервиса Lambda.
Tasks-lambda#
Примеры возможного функционала:
- открепить лица от списка, если лица не похожи на указанное лицо
- удалить дубликаты лиц из списка
- рекурсивно найти события, похожие на указанное изображение
Во время своей работы, Tasks-lambda будет взаимодействовать со следующими сервисами LUNA PLATFORM:
- Configurator
- Faces
- Python Matcher
- Remote SDK
- Tasks
- Events*
- Image Store*
- Handlers*
* сервис может быть отключен в настройке "ADDITIONAL_SERVICES_USAGE"
После создания lambda необходимо выполнить запрос "lambda task" для создания задачи Lambda. Результаты задачи/подзадачи можно получить с помощью стандартных запросов сервиса Tasks.
Задача Lambda создается согласно общему процессу создания задач, за исключением того, что вместо "рабочего процесса" Tasks используется сервис Lambda.
При написании кода для Tasks-lambda рекомендуется разбивать каждую задачу на подзадачи для удобства представления процесса и распараллеливания выполнения задач.
При необходимости можно создать расписание для Tasks-lambda.
См. подробную информацию и примеры кода для Tasks-lambda, в разделе "Tasks lambda development" руководства разработчика сервиса Lambda.
Создание lambda#
Для создания lambda требуется выполнить следующие действия:
- Написать код на языке Python в соответствии с типом будущей lambda и требованиями к коду.
- Переместить файлы в архив в соответствии с требованиями к архиву.
- Выполнить запрос "create lambda", указав следующие обязательные данные:
- "archive" — адрес до архива с пользовательским модулем;
- "credentials" > "lambda_name" — имя для создаваемой lambda;
- "parameters" > "lambda_type" — тип создаваемой lambda ("handlers", "standalone" или "tasks").
Также опционально в секции "deploy_parameters" можно задать количество подов, выделить ресурсы на поды, задать пространства имен (namespace), а также включить использование GPU.
Кроме того можно задать метки для запуска lambda с использованием конкретных узлов Kubernetes с помощью параметра "deploy_parameters" > "selector". Это позволяет более детально контролировать развертывание lambda, позволяя администраторам указывать узлы, на которых должны быть размещены lambda в зависимости от их потребностей в ресурсах. Применяя метки к узлам Kubernetes и используя параметр "selector", администраторы могут управлять выделением ресурсов не только для отдельных lambda, но и для групп lambda с аналогичными требованиями к ресурсам.
При необходимости можно задать список дополнительных команд Docker для создания lambda-контейнера. См. раздел "Lambda — Archive requirements" сервиса Lambda руководства разработчика.
В ответе на успешный запрос будет выдан идентификатор "lambda_id".
Создание lambda состоит из нескольких этапов, а именно:
- создание образа Docker:
- получение предоставленного ZIP-архива;
- дополнение архива необходимыми файлами;
- сохранение архива в хранилище S3;
- публикация образа в реестр (registry).
- создание сервиса в кластере Kubernetes.
Во время создания lambda можно выполнять следующие запросы:
- "get lambda image creation status" для получения статуса создания образа Docker ("in_progress", "error", "completed", "not_found")
- "get lambda image creation logs" для получения логов создания образа Docker
- "get lambda status" для получения статуса создания lambda ("running", "waiting", "terminated", "not_found")
См. диаграмму последовательности создания lambda в разделе "Диаграмма создания lambda".
См. подробное описание процесса создания lambda в разделе "Creation pipeline" руководства разработчика сервиса Lambda.
Создание обработчика для Handlers-lambda#
Если предполагается использовать lambda как пользовательский обработчик, имитирующий ответ классического обработчика, то необходимо создать обработчик, указав "handler_type" = "2" и полученный "lambda_id".
Во время создания обработчика, сервис Handlers выполнит проверку работоспособности (healthcheck) до кластера Kubernetes.
Полученный "handler_id" может быть использован в запросах "generate events" или "estimator task".
Использование lambda#
В таблице ниже приведены ресурсы для работы с lambda в зависимости от её типа.
| Ресурс | Тип lambda | Формат тела запроса и ответа |
|---|---|---|
| "/lambdas/{lambda_id}/proxy" | Standalone-lambda, Handlers-lambda с собственной схемой ответа | Собственные |
| "/handlers/{handler_id}/events" | Handlers-lambda | Соответствующие спецификации OpenAPI |
| "/tasks/estimator" | Handlers-lambda | Соответствующие спецификации OpenAPI |
См. диаграмму последовательности обработки lambda в разделе "Диаграмма обработки lambda".
Каждая lambda имеет свой собственный API, описание которого также доступно с помощью запроса "get lambda openapi documentation".
Каждый ответ lambda будет содержать несколько заголовков, включая:
- "Luna-Request-Id" — классический внешний идентификатор запроса LUNA PLATFORM;
- "Lambda-Version" — содержит текущую лямбда-версию.
Полезные запросы при работе с lambda:
- "get lambda status" для получения статуса создания lambda ("running", "waiting", "terminated", "not_found", "pending")
- "get lambda" для получения полной информации о созданной lambda (время создания, имя, статус и пр.)
- "get lambda logs" для получения логов создания lambda
Создание lambda с поддержкой GPU#
Доступна возможность создания lambda, которая может использовать ресурсы графического процессора. Для возможности использования GPU, в запросе на создание lambda должен быть включен параметр "deploy_parameters" > "enable_gpu".
Lambda поддерживает только графические процессоры NVIDIA. Для получения дополнительной информации об использовании графических процессоров см. документацию по Kubernetes.
Если доступен только один графический процессор, но требуется больше, можно включить общий доступ к графическому процессору (см. официальную документацию).
Сервис Lambda не управляет ресурсами кластера, включая выделение графических процессоров (GPU). Управление ресурсами осуществляется администратором Kubernetes.
Кроме того, при разворачивании LUNA PLATFORM в Kubernetes рекомендуется настроить манифест определенным образом для всех контейнеров, использующих GPU (включая контейнер сервиса Lambda) во избежание проблем с видимостью устройств. См. подробную информацию в разделе "Настройка манифеста для поддержки GPU" руководства по установке.
Обновление lambda#
Базовый образ для контейнеров lambda периодически обновляется. Этот образ содержит необходимые модули для взаимодействия с сервисами LUNA PLATFORM. Для применения обновлений требуется пересоздать lambda, чтобы контейнер мог быть перестроен на основе нового образа. После обновления базового образа и библиотеки "luna-lambda-tools", функциональность lambda может быть нарушена.
Можно обновить lambda с помощью запроса "update lambda", используя последний базовый образ. Рекомендуется иметь резервную копию архива на S3.
См. подробную информацию про механизм обновления, стратегии резервного копирования и восстановление из резервной копии в разделе "Lambda updates" руководства разработчика сервиса Lambda.
Backport 3#
Сервис Backport 3 используется для обработки запросов LUNA PLATFORM 3 с помощью LUNA PLATFORM 5.
Несмотря на то, что большинство запросов выполняется так же, как в LUNA PLATFORM 3, имеются ограничения. Более подробная информация приведена в разделе "Функции и ограничения Backport 3".
Более подробная информация об API Backport 3 приведена в "Backport3ReferenceManual.html".
Новые ресурсы Backport 3#
Оценка Liveness#
Backport 3 выполняет оценку Liveness в дополнение к функциям LUNA PLATFORM 3. См. раздел "liveness > predict liveness" в спецификации OpenAPI сервиса .
Обработчики#
В сервисе Backport 3 предусмотрено несколько обработчиков: extractor, identify, verify. С помощью этих обработчиков можно выполнить несколько действий в одном запросе:
-
"handlers" > "face extractor" – можно извлечь БШ из изображения, создать персону с этим БШ, добавить персону в заранее определенный список.
-
"handlers" > "identify face" – можно извлечь БШ из изображения и сравнить БШ с предопределенным списком кандидатов.
-
"handlers" > "verify face" – можно извлечь БШ из изображения и сравнить БШ с БШ персоны.
См. описание персон в документации LUNA PLATFORM 3.
Описание обработчиков и все параметры обработчиков приведены в следующих разделах:
- "handlers" > "patch extractor handler"
- "handlers" > "patch verify handler"
- "handlers" > "patch identify handler"
Запросы основаны на обработчиках и в отличие от стандартных запросов "descriptors" > "extract descriptors", "matching" > "identification", и "matching" > verification», приведенные выше запросы являются более гибкими.
Можно изменить уже существующие обработчики, добавив оценку дополнительных параметров в запросы. Например, можно указать пороговые значения углов положения головы или включить/выключить оценку базовых атрибутов.
Обработчики создаются для каждой новой учетной записи в момент ее создания. Созданные обработчики содержат параметры по умолчанию.
У каждого обработчика есть соответствующий обработчик в сервисе Handlers. Параметры обработчиков хранятся в базе данных luna_backport3.
Каждый обработчик поддерживает запросы GET и PATCH, поэтому можно получать и обновлять параметры всех обработчиков.
У каждого обработчика есть своя версия. Версия увеличивается с каждым PATCH запросом. При удалении текущего обработчика, версия сбрасывается до 1:
-
Для запросов с методами POST и GET:
Если в сервисе Handlers и/или Backport 3 нет обработчика для указанного действия, он создается с параметрами по умолчанию.
-
Для запросов с PATCH методами:
Если в сервисе Handlers и/или Backport 3 нет обработчика для указанного действия, создается новый обработчик включающий набор политик по умолчанию и набор политик из запроса.
Архитектура Backport 3#
Сервис Backport 3 взаимодействует с сервисом API и с помощью него отправляет запросы в LUNA PLATFORM 5. В свою очередь сервис API взаимодействует с сервисом Accounts для проверки аутентификационных данных.
У сервиса Backport 3 есть своя собственная база данных (см. "Описание базы данных Backport3"). Некоторые из его таблиц приравниваются к таблицам базы данных Faces LP 3. Это позволяет создавать и использовать такие же сущности (лица, токены аккаунтов и аккаунты), которые существовали в LP 3.
Сервис Backport использует Image Store для хранения портретов (см. описание портретов в документации LUNA PLATFORM 3).
Настроить Backport 3 можно с помощью сервиса Configurator.
Функции и ограничения Backport 3#
Следующие функции имеют основные отличия:
Для следующих ресурсов при использовании метода POST по умолчанию задана 56 версия биометрических шаблонов:
-
/storage/descriptors -
/handlers/extractor -
/handlers/verify -
/handlers/identify -
/matching/search
Тем не менее, можно загрузить существующие БШ версий 52, 54, 56. Более старые версии БШ больше не поддерживаются.
-
Оценка параметра saturation больше не поддерживается для ресурса /storage/descriptors при отправке запроса с методом POST, значение всегда устанавливается равным 1.
-
Для ресурса /storage/descriptors при отправке запроса с методом POST оценка атрибута eyeglasses больше не поддерживается. В структуре attributes в ответе не будет параметра eyeglasses.
-
Для ресурса /storage/descriptors при отправке запроса с методом POST пороговые значения угла положения головы по-прежнему можно отправлять в качестве плавающих значений в диапазоне [0, 180], но они будут автоматически округлены до целых значений. Как и раньше, пороги вне диапазона [0, 180] не учитываются.
Модуль сбора мусора (Garbage collection)#
Согласно логике LUNA Platform 3, мусор – это биометрические шаблоны, которые не связаны ни с персонами, ни со списками.
Для нормальной работы системы необходимо регулярно удалять мусор из баз. Для этого требуется запустить скрипт очистки системы remove_not_linked_descriptors.py из директории ./base_scripts/gc/.
Согласно архитектуре Backport 3, с помощью этого скрипта из сервиса Faces удаляются лица, которые не связаны с какими-либо персонами или списками из базы данных Luna Backport 3.
Процесс выполнения скрипта#
Процесс выполнения скрипта состоит из нескольких этапов:
1) В базе данных Faces создается временная таблица. См. дополнительную информацию о временных таблицах для oracle или postgres. 2) Получаются ID лиц, не привязанных к спискам. ID хранятся во временной таблице. 3) Пока временная таблица содержит данные, выполняются следующие операции:
- Получается пакет ID из временной таблицы. Получаются первые 10 тыс. (или меньше) идентификаторов лиц.
- Получаются
filtered ids– идентификаторы, которых нет в таблицеperson_faceбазы данных Backport 3. Filtered idsудаляются из базы данных Faces. Если некоторые лица не удается удалить, выполнение скрипта останавливается.Filtered idsудаляются из базы данных Backport 3 (foolcheck). Выводится предупреждение.- ID удаляются из временной таблицы.
Запуск скрипта GC#
docker run --rm -t --network=host --entrypoint bash dockerhub.visionlabs.ru/luna/luna-backport-3:v.0.11.40 -c "python3 ./base_scripts/gc/remove_not_linked_descriptors.py"
Результат будет содержать информацию о количестве удаленных лиц и количестве людей с лицами.
Backport 4#
Сервис Backport 4 используется для обработки запросов LUNA PLATFORM 4 с помощью LUNA PLATFORM 5.
Несмотря на то, что большинство запросов выполняется так же, как в LUNA PLATFORM 4, все же есть некоторые ограничения. Более подробная информация приведена в разделе "Функции и ограничения Backport 4".
Более подробна информация о сервисе API Backport 4 приведена в спецификации OpenAPI сервиса Backport 4.
Архитектура Backport 4#
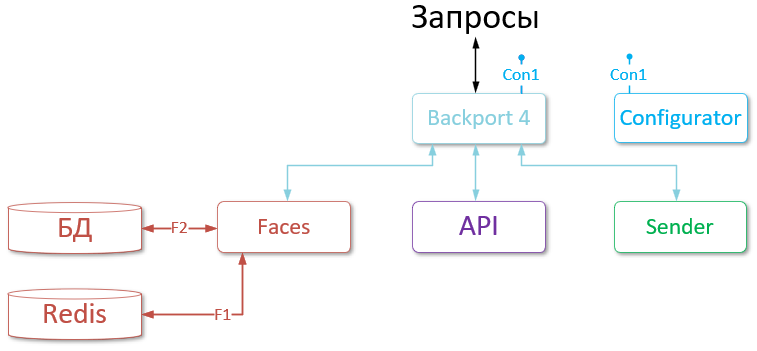
Сервис Backport 4 взаимодействует с сервисом API и с помощью него отправляет запросы в LUNA PLATFORM 5.
Backport 4 напрямую взаимодействует с сервисом Faces для получения информации о количестве существующих атрибутов.
Backport 4 напрямую взаимодействует с сервисом Sender. Все запросы к сервису Sender отправляются с помощью сервиса Backport 4. См. запрос "ws" > "ws handshake" в спецификации OpenAPI сервиса Backport 4.
Настроить Backport 4 можно с помощью сервиса Configurator.
Функции и ограничения Backport 4#
Следующие функции имеют основные отличия:
Текущие версии сервисов LUNA PLATFORM выдаются по запросу к ресурсу /version. Например, выдаются версии следующих сервисов:
- "luna-faces"
- "luna-events"
- "luna-image-store"
- "luna-python-matcher" или "luna-matcher-proxy"
- "luna-tasks"
- "luna-handlers"
- "luna-api"
- "LUNA PLATFORM"
- "luna-backport4" – текущая версия
Журнал изменений ресурсов:
- Ресурс
/attributes/countдоступен без каких-либо параметров запроса и не поддерживает аккаунтинг. Ресурс работает с временными атрибутами. - Ресурс
/attributesпо методу GET: допускается параметр запросаattribute_idsвместо параметров запросаpage,page_size,time__ltиtime__gte. Таким образом, можно получать атрибуты по их идентификаторам, а не по фильтрам. Ресурс работает с временными атрибутами. - Ресурс
/attributes/<attribute_id>по методам GET, HEAD, DELETE и ресурс/attributes/<attribute_id>/samplesпо методу GET взаимодействуют с временными атрибутами и выдают данные атрибутов, если срок действия атрибута не истек. В противном случае выдается ошибка "Not found". - Если уже использован атрибут для создания лица, необходимо использовать
face_idдля получения данных атрибута. В этом случаеattribute_idиз запроса эквивалентенface_id. - С помощью ресурса
/facesможно создавать несколько лиц с одним и тем жеattribute_id. - С помощью ресурса
/faces/<face_id>по методу DELETE можно удалить лицо без удаления его атрибута. - С помощью ресурса
/faces/<face_id>по методу PATCH можно изменить атрибут лица, сделав первый запрос на изменениеevent_id,external_id,user_data,avatar(при необходимости) и второй запрос на изменение атрибута (при необходимости). - Если необходимо изменить
attribute_idлица, сервис попытается изменить его с помощью данных временного атрибута, если временный атрибут существует. Или же сервис попытается изменить его с помощью данных атрибутов лица сface_id=attribute_id. - Политика сравнения ресурсов
/handlersтеперь имеет ограничение на сравнение по умолчанию, которое задано с помощью настройкиMATCH_LIMITиз файла config.py сервиса Backport 4. - Ресурс
/events/statsпо методу POST: использованиеattribute_idв объектеfiltersзапрещено, так как это поле больше не хранится в базе данных. Будет выдаваться ответ со статус кодом 403. Attribute_idв событиях не пустой и равенface_idдля обратной совместимости. Задача Garbage collection недоступна, поскольку все атрибуты временны и будут удаляются автоматически. По запросу к ресурсу/tasks/gcвыдается статус код 400.- Столбец
attribute_idне добавляется в задачу Reporter, а также этот столбец игнорируется, если он указан в запросе. Столбцыtop_similar_face_id,top_similar_face_list,top_similar_face_similarityзаменяются столбцом top_match в отчете, если какой-либо из этих столбцов передается в запросе задачи Reporter. - В результате выполнения задачи Linker всегда создаются новые лица из событий и игнорируются лица, созданные при запросе обработки событий.
- Ресурс
/matcherне проверяет наличие указанных лиц, поэтому ошибкаFacesNotFoundникогда не выдается. Если пользователь укажет несуществующего кандидата типа «faces», сообщения об ошибке не будет, и не будет выполнено фактическое сравнение с этим лицом. - Ресурс
/matcherпроверяет, есть ли у эталона с атрибутом типа идентификатор атрибута лица или идентификатор временного атрибута, и выполняет подстановку типа. Следовательно, он обеспечивает отправку эталонов для сравнения таким же способом, как это было сделано в предыдущей версии. - Ресурс
/matcherучитывает ограничения сравнения. По умолчанию максимальное количество эталонов или кандидатов ограничено 30. Если необходимо превысить эти ограничения, следует настроить параметрыREFERENCE_LIMITиCANDIDATES_LIMIT. - Добавлен ресурс
/ws. В LUNA PLATFORM 4 API не было ресурса/ws, поскольку это был отдельный ресурс сервиса Sender. Этот добавленный ресурс аналогичен ресурсу сервиса Sender, за исключением того, чтоattribute_idлиц кандидатов аналогиченface_id. - Ресурс
/handlersвыдает ошибку "Invalid handler with id {handler_id}", если обработчик был создан в LUNA PLATFORM 5 API и не поддерживается в LUNA Backport 4.
Пользовательский интерфейс Backport 4#
Сервис пользовательского интерфейса используется для визуального представления функций LP. Он не содержит все функции, имеющиеся в LP. С помощью пользовательского интерфейса можно:
- Загружать фотографии и создавать лица с их помощью;
- Создавать списки;
- Сравнивать имеющиеся лица;
- Показать имеющиеся события;
- Показать имеющиеся обработчики.
Вся информация в пользовательском интерфейсе отображается в соответствии с данными аккаунта, указанными в файле конфигурации сервиса пользовательского интерфейса (../Imgs/Install/luna-ui/browser/env.js).
Пользовательский интерфейс работает одновременно только с одним аккаунтом, который должен иметь тип "user".
Необходимо открыть браузер и ввести адрес пользовательского интерфейса. Значение по умолчанию:
Можно выбрать страницу в левой части окна.
Страница списков/лиц#
Стартовая страница пользовательского интерфейса — Lists/Faces. На ней есть все лица и списки, созданные с помощью указанного в конфигурации аккаунта.
В левом столбце рабочей области отображаются имеющиеся списки. Можно создать новый список, нажав кнопку Add list. В появившемся окне можно указать данные пользователя для списка.
В правом столбце показаны все созданные лица с разбивкой на страницы.
С помощью кнопки Add new faces можно создать новые лица.
На первом этапе необходимо выбрать фотографии, из которых будут созданы лица. Можно выбрать одно или несколько изображений с одним или несколькими лицами на них.
После выбора изображений в новом диалоговом окне будут показаны все найденные лица.
Все правильно предварительно обработанные изображения будут иметь отметку Done. Если изображение не соответствует ни одному из требований, для него будет отображаться ошибка.
Доступна кнопка Next step.
На следующем этапе необходимо выбрать атрибуты, которые нужно извлечь для лиц.
Для этого нужно нажать кнопку Next step.
На следующем этапе необходимо указать данные пользователя и внешний идентификатор (external_id) для каждого лица. Также можно выбрать списки, в которые будет добавлено каждое лицо. Для создания лиц нужно нажать кнопку Add Faces.
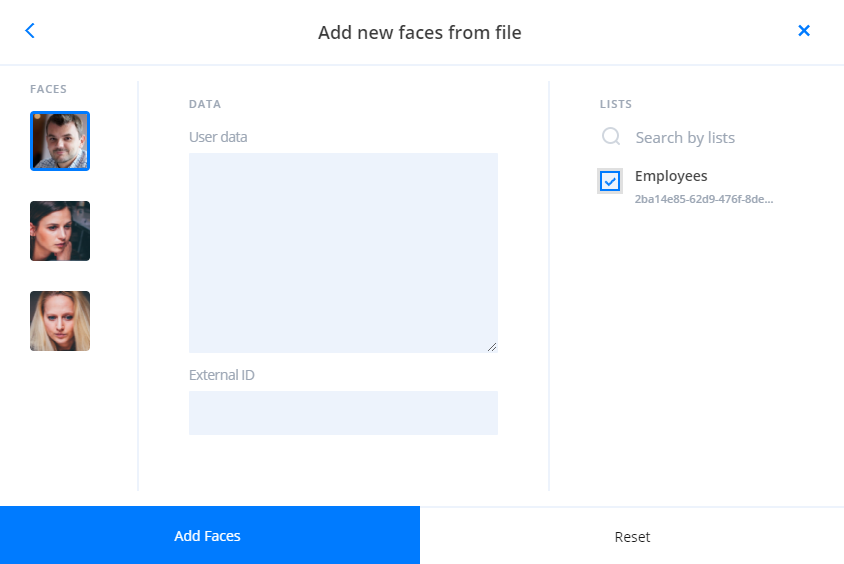
Страницы можно менять с помощью кнопок со стрелками.

Можно изменить отображение лиц и отфильтровать их с помощью кнопок в правом верхнем углу.
Фильтр лиц. Можно фильтровать лица по идентификатору, внешнему идентификатору или идентификатору списка;
/
![]()
Изменение вида имеющихся лиц.
Страница сервиса Handlers#
На странице Handlers отображаются все обработчики, созданные с помощью указанного в конфигурации аккаунта.
Вся информация об указанных политиках обработчика отображается при выборе обработчика.
Можно отредактировать или удалить обработчик с помощью значков редактирования 
и удаления 
.
Страница сервиса Events#
На странице Events отображаются все события, созданные с помощью указанного в конфигурации аккаунта.
Также на ней есть фильтры для отображения событий ![]()
.
Общая информация#
Можно отредактировать или удалить элемент (лицо, список или обработчик) с помощью соответствующих значков
и
. Значки появляются при наведении курсора на элемент.

Диалог сравнения#
С помощью кнопки Matching в нижнем левом углу окна можно выполнить сравнение.
После нажатия на кнопку можно выбрать количество полученных результатов для каждого эталона.

На первом этапе необходимо выбрать эталоны для сравнения. Можно выбрать лица и/или события в качестве эталонов.
На втором этапе необходимо выбрать кандидатов для сравнения. Можно выбрать лица или списки в качестве кандидатов.
На последнем этапе необходимо нажать кнопку Start matching, чтобы получить результаты.

Потребление ресурсов сервисами#
Ниже приведена таблица, описывающая наиболее значительное потребление ресурсов сервисами. Сервисы Remote SDK и Python Matcher выполняют наиболее ресурсозатратные операции.
|
Сервис |
Наиболее потребляемые ресурсы |
|---|---|
|
Remote SDK |
CPU, RAM, GPU Сервис Remote SDK выполняет математическое преобразование изображений и извлечение биометрических шаблонов. Эти операции требуют значительных вычислительных мощностей. Для вычислений можно использовать как CPU, так и GPU. Использование GPU предпочтительно, т.к. обработка запросов происходит эффективнее. Однако, поддерживаются не все типы видеокарт. |
|
Python Matcher |
CPU, RAM Python Matcher выполняет сравнение по спискам. Сравнение требует ресурсов CPU, однако также следует выделить максимально возможный объем RAM под каждого экземпляра Python Matcher. RAM используется для хранения биометрических шаблонов, полученных из базы данных. Таким образом, сервису Python Matcher не требуется запрашивать каждый БШ из базы данных. При распределении экземпляров на нескольких серверах следует учитывать производительность каждого сервера. Например, если крупная задача выполняется несколькими экземплярами Python Matcher, а один из них находится на сервере с низкой производительностью, выполнение всей задачи в целом может замедлиться. |
|
Postgres |
SSD, CPU, RAM |
|
Image Store |
SSD, CPU, RAM |
|
Handlers |
CPU |
|
Tasks |
RAM |
|
API |
CPU |
|
Faces |
CPU |
|
Events |
CPU |
|
Backport 3 |
CPU |
|
Backport 4 |
CPU |
|
Lambda |
RAM, CPU Количество RAM зависит от размера передаваемого архива. См. раздел "Сервис Lambda". |
|
Sender, Admin, Accounts, Licenses |
В обычных сценариях не должны потреблять много ресурсов. |